Spark是基于内存的计算框架,它主要包括SparkCore,SparkSQL,SparkML,SparkStreaming等方面的内容,本文从资源调度,任务调度,广播变量以及累加器这几个方面来介绍SparkCore
Stage
RDD的宽窄依赖
宽依赖(shuffle依赖)
父RDD与子RDD的partition之间是一对多的关系
窄依赖
父RDD与子RDD的partition之间是一对一或多对一的关系
补充
- partition之间的对应关系是从父RDD的角度来考虑的
- Shuffle 指的是节点或者分区之间数据传输的过程
- 常见的shuffle算子有
byKey字样的,distinct以及join类算子等,Shuffle类算子可以手动指定分区数量也可以利用默认的分区数量,比如 join 后的默认分区数量是RDD分区数多的那个
相关术语
资源层面
- Cluster Manager — 在集群上获取资源的外部服务(比如Standalone, Yarn, Mesos)
- Driver Program — 用来连接Worker进程的程序
- Master(Standalone) — 资源管理的主节点(进程)
- Worker(Standalone) — 资源管理的从节点(进程)或者称为管理本机资源的进程
- Executor — 是在一个Worker进程所管理的节点上为某个Application启动的一个进程,该进程负责执行Task,并且负责将数据存在内存或磁盘上,每个Application都用各自独立的Executor
任务层面
- Application — 基于Spark的用户程序,包含了Driver程序和运行在集群上的Executor程序
- Job — 包含很多Task的并行计算,与Action算子一一对应
- Stage — 一个Job会被拆分成多组Task,每组Task就称为Stage,类似于MapReduce分Map Task和Reduce Task
- Task — 被送到Executor上的工作单元
Stage的生成
根据RDD之间的宽依赖可以划分成不同的Stage, Stage是是由一组并行的Task组成
Stage的并行度
- Stage的并行度由最后一个RDD的partition个数决定
- 通过增大RDD的partition个数来提高Stage的并行度,比如通过一些RDD算子
reduceByKey(xxxx, numPartition) |
Spark计算模式
管道(pipeline)计算模式,即1+1+1=3的形式(MapReduce的计算模式是1+1=2,2+1=3),比如
# 管道数据在shuffle write或者对RDD进行持久化的时候会落地 |
Spark提交任务
基于Standalone-client模式提交任务
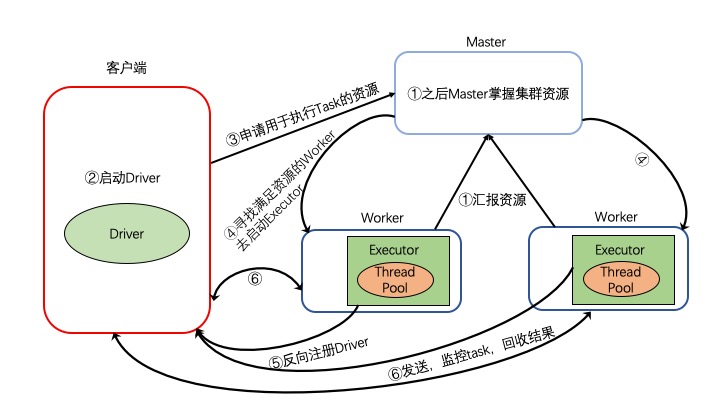
执行流程
- 集群启动,Worker向Master汇报资源,Master掌握集群资源
- 在客户端提交Spark application后 ,在客户端首先启动Driver
- 客户端向Master申请执行Task资源
- Master会找到满足资源的Worker节点,启动Executor
- Exeuctor启动之后会反向注册给Driver
- Driver发送,监控Task并回收结果
执行流程图
注意
- 优点
在客户端可以看到Task的执行和结果 - 缺点
当在客户端提交多个Application时,有网卡流量激增的问题 - 使用场景
client 模式适用于程序测试,不适用于生产环境
基于Standalone-cluster模式提交任务
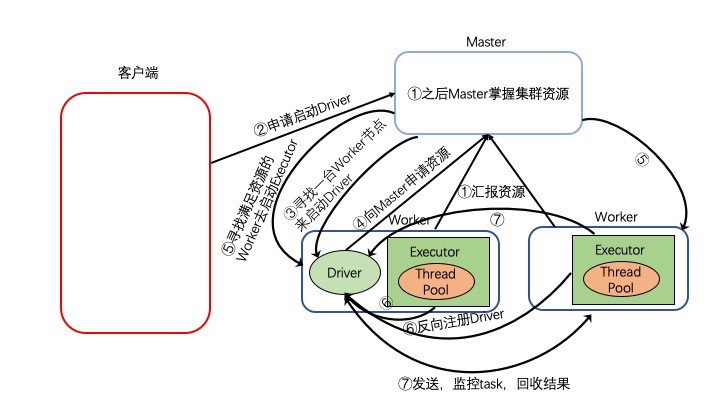
执行流程
- 集群启动,Worker向Master汇报资源,Master掌握集群资源
- 在客户端提交Spark application后 ,在客户端申请启动Driver
- 寻找一台满足启动Driver的Worker节点去启动Driver
- 客户端向Master申请执行Task资源
- Master会找到满足资源的Worker节点,启动Executor
- Exeuctor启动之后会反向注册给Driver
- Driver发送,监控Task并回收结果
执行流程图
注意
- 优点
当在客户端提交多个Application时,将网卡流量激增的问题分散到集群中 - 缺点
在客户端可以看不到Task的执行和结果,要去WebUI中查看 - 使用场景
cluster模式适用于生产环境
基于Yarn-client模式提交任务
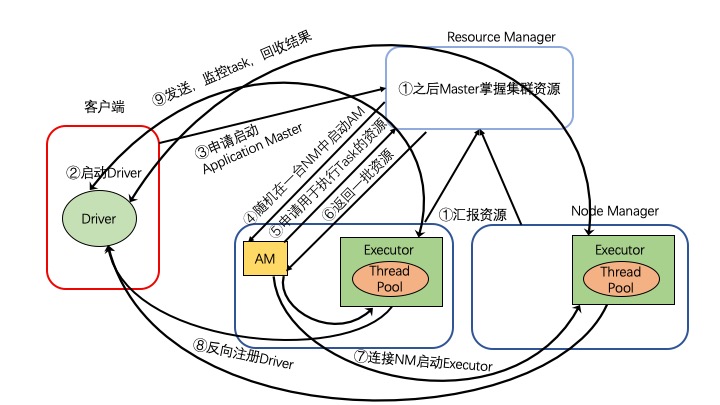
执行流程
- 集群启动,Worker向Master汇报资源,Master掌握集群资源
- 在客户端提交Spark application后 ,在客户端首先启动Driver
- 客户端向Resource Manager(RM)申请启动Application Master(AM)
- RS收到请求之后,随机在一台NM中启动AM
- AM启动之后,会向RS申请资源
- RS返回一批NM资源
- AM连接这些NM启动Executor
- Executor启动之后,会反向注册给Driver
- Driver发送,监控Task并回收结果
执行流程图
注意
- 优点
在客户端可以看到Task的执行和结果 - 缺点
当在客户端提交多个Application时,有网卡流量激增的问题 - 使用场景
client模式适用于程序测试,不适用于生产环境
基于Yarn-cluster模式提交任务
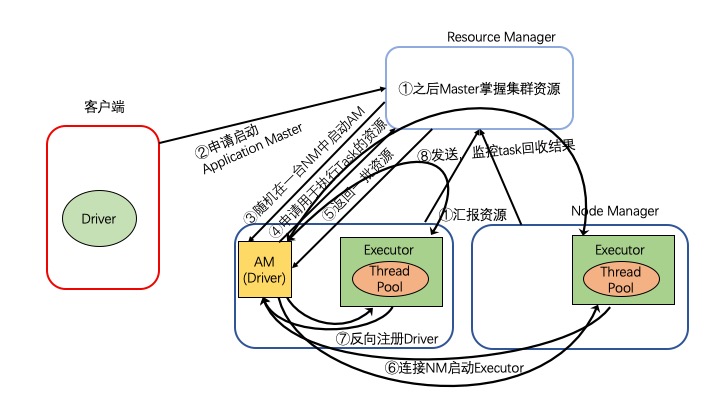
执行流程
- 集群启动,Worker向Master汇报资源,Master掌握集群资源
- 客户端向Resource Manager(RM)申请启动Application Master(AM)
- RS收到请求之后,随机在一台NM中启动AM
- AM(Driver)启动之后,会向RS申请资源
- RS返回一批NM资源
- AM连接这些NM启动Executor
- Executor启动之后,会反向注册给Driver
- Driver发送,监控Task并回收结果
执行流程图
注意
- 优点
当在客户端提交多个Application时,将网卡流量激增的问题分散到集群中 - 缺点
在客户端可以看不到Task的执行和结果,要去WebUI中查看 - 使用场景
cluster模式适用于生产环境
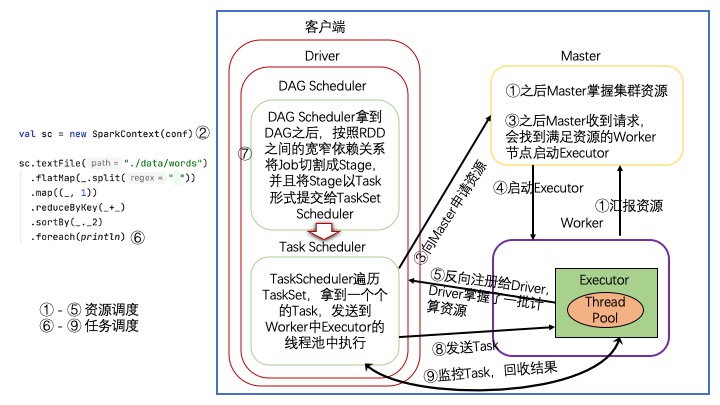
资源调度&任务调度
调度流程
- 集群启动,Worker向Master汇报资源,Master掌握集群资源
- 在客户端提交Spark application ,当执行new SparkContext后,在客户端首先启动Driver,并创建 DAGScheduler 和 TaskScheduler(其中DAGScheduler和TaskScheduler分别是高层调度器和底层调度器)
- TaskScheduler向Master申请执行Task资源
- Master会找到满足资源的Worker节点,启动Executor
- Exeuctor启动之后会反向注册给Driver,Driver掌握了一批计算资源
- Action算子触发Job,Job根据RDD之间的依赖关系形成DAG(即Lineage构成的有向无环图)
- DAGScheduler 拿到DAG后,按照RDD之间的宽窄依赖关系将Job切割成Stage,并且将Stage以TaskSet形式提交给TaskScheduler
- TaskScheduler遍历TaskSet,拿到一个个的Task,发送到Worker中Executor的线程池执行
- TaskScheduler监控Task,回收结果
调度流程图
补充
- TaskSchedualer将Task发送到Worker失败的话,会重新发送,如果发送3次都失败的话,Task对应的Stage就失败了,那么DAGSchedualer会重新发送Stage,如果重试了4次都失败的话,Stage对应的Job就失败了,Job对应的Application(由很多job组成)就失败了,之后即将执行的Job也都不执行了,但之前的job执行的结果不会回退
- 针对Straggling Task(执行缓慢的Task)会启动推测执行机制,也就是重新启动一个一摸一样的Task,最后以执行速度快的Task的结果为准,比如:处理10G的数据,8G已处理并存储完毕,还剩2G,那么重启的Task也要重新计算10G的数据,如果有ETL(抽取转换加载)行为,一定要关闭推测执行机制,因为有可能存在数据重复存储,当节点负载压力不平衡的时候可以使用推测执行机制,推测执行机制默认是关闭的
粗力度细粒度资源申请
粗粒度申请
- 定义
在Application的Task执行之前需要将所有的资源申请完毕,如果申请不到则一直处于等待状态,直到资源申请完毕之后才会执行任务,这样Task执行的时候就不需要自己申请资源,加快了Task的执行效率。Task执行快了,Job就快了,Application也就快了。但是必须要等最后一个Task执行完毕之后,资源才会被释放 - 优点
Application执行快 - 缺点
集群资源不能充分利用
细粒度申请
- 定义
在Application的Task执行之前不会将所有的资源申请完毕,Task执行的时候需要自己申请资源,自己释放资源,这样导致Task执行相对慢 - 优点
集群资源可以充分利用 - 缺点
Application执行相对慢
广播变量
提出背景
如果每一个task都要用到list的时候,那么当task的数量过多的时候就会造成资源浪费的问题,比如:100个task,就要传输100个list,并且都要保存在executor中,这样就会造成大量资源(内存)被占用
介绍
为了解决上述问题引入了广播变量,将变量广播出去之后,在Executor中的block manager中就有相应的广播变量,之后每次Task传输的时候不需要携带广播变量。如果在Executor中需要广播变量的话,那么就可以block manager中寻找需要的广播变量
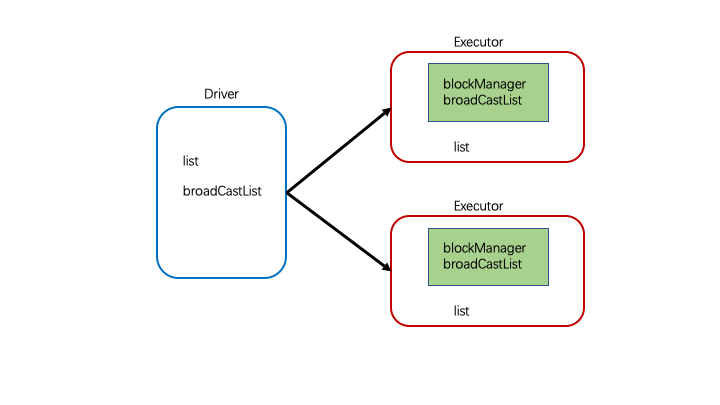
val list: Seq[String] = List[String]("zhangsan","lisi") |
注意
- 不能将RDD广播出去,但是可以将RDD的结果广播出去,比如:可以将rdd.collect()广播出去
- 广播变量在Driver中定义,在Executor中使用,**但是绝不能在Executor中改变广播变量的值
累加器
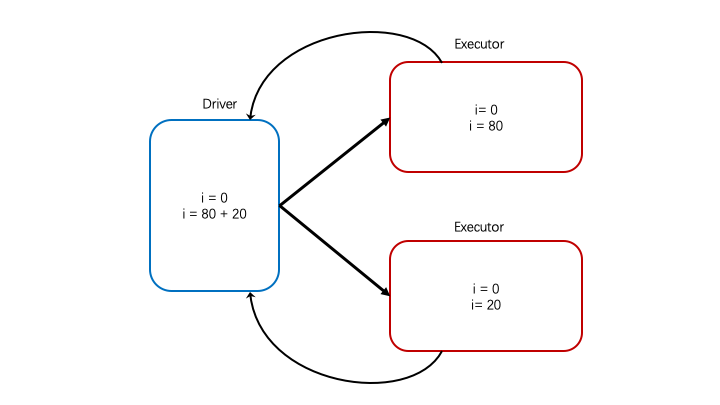
提出背景
val i = 0 |
在driver端打印的i是原本就存在于driver端的i,所以无法统计一共map了多少次
介绍
为了解决上述问题引入了累加器,有了累加器之后,我们就可以将各个分区的i加在一起
object AccumulatorTest { |
注意
- 2.x版本的spark可以在Executor端通过 .value查看累加器的值,或者直接打印对象accum查看累加器的值, 但是在1.6的spark中,Executor端无法通过 .value查看累加器的值,只能通过对象来获取值
- 累加器不是全局变量,因为分布式没有全局变量(只有在一台机器才会有全局的概念)
- 在Driver端定义累加器的对象的时候,初始值为1
- 在Executor中永远拿不到sparkContext对象,因为sparkContext不允许传到Executor中