本文记录了小编在学习Scala的过程中总结的知识点以及常用语法
Scala介绍
官网通过上述6个方面来对Scala进行介绍,我对Scala这6大特性的理解如下
| 特性 | 描述 |
|---|---|
| Seamless Java Interop | Java和scala可以混编 |
| Type Inference | 支持类型自动推断 |
| Concurrency & Distribution | 支持并发和分布式,比如Actors的应用 |
| Traits | 特质,相当与Java中的接口和抽象类的结合,因为在特质中方法体可实现也可不实现相当于Java的抽象类,可以多继承相当于Java的接口 |
| pattern matching | 模式匹配,相当于Java中的switch |
| Higher-order functions | 支持高阶函数,比如隐函数等 |
Scala基础
数据类型
Scala支持的所有数据类型如下
| 数据类型 | 描述 |
|---|---|
| Byte | 8 bit 有符号数字 |
| Short | 16 bit 有符号数字 |
| Int | 32 bit 有符号数字 |
| Long | 64 bit 有符号数字 |
| Float | 32 bit 单精度浮点数 |
| Double | 64 bit 双精度浮点数 |
| Char | 16 bit Unicode字符 |
| Boolean | 布尔类型 |
| String | 字符串 |
| Unit | 无返回值的函数类型,相当于Java的void |
| Null | 空值或者空引用 |
| Nothing | 所有类型的子类,表示没有值 |
| Any | 所有类型的超类,任何实例都属于Any类型 |
| AnyRef | 所有饮用类型的超类 |
| AnyVal | 所有值类型的超类 |
其中容易混淆的“空”类型
| 数据类型 | 描述 |
|---|---|
| Null | Trait,其唯一的实例就是null,是AnyRef的子类,不是AnyVal的子类 |
| Nothing | Trait,所有类型(包括AnyRef和AnyVal)的子类,没有实例 |
| None | Option的两个子类之一,另一个子类是Some |
| Unit | 无返回值的函数类型,相当于Java的void |
| Nil | 长度为0的List |
各数据类型之间的继承关系为
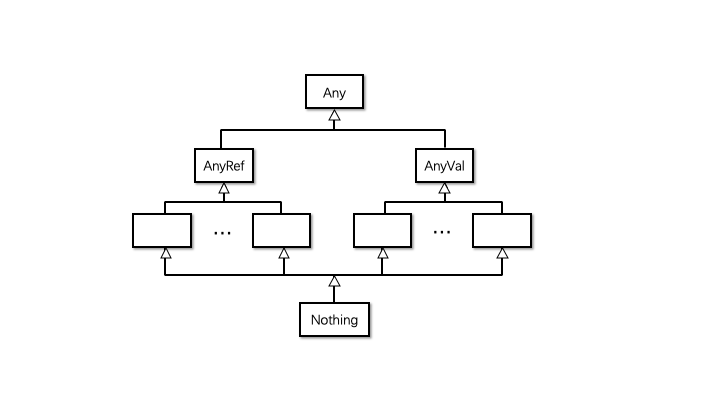
Note
(1) Nothing 会在类型推断的时候用到,当无法自动推断类型的时候会数据类型写成Nothing,比如
scala> val a = List() |
(2) Scala的数据类型是强类型,所以不同数据类型之间判断是否相等的结果一定是false,比如
scala> 'r' == "r" |
返回结果为false
代码实现
object Lesson_Base { |
Scala类和对象
基础知识
- Scala 中的 object 是单例对象,单例对象是一种特殊的类,当它定义于顶层时(即没有包含在其他类中),有且只有一个实例。当对象定义在一个类或方法中时和惰性变量一样是延迟创建的,即当它第一次被使用时创建。相当于 Java 中的工具类,object 中定义的全是静态,因此一定都会被加载,这也是 main 方法要写在 object 中的原因。
- Scala 中定义变量使用 var,常量使用val,变量可变,常量不可变(定义变量的时候尽量使用val,便于回收)
- Scala中每行后面都会有分号自动推断机制,所以不用每行后面写分号;因为有类型自动推断机制,所以变量和常量类型不用写
- Scala 中命名建议类名首字母大写 ,方法首字母小,都使用驼峰命名法
- Scala 中class可以传参数,传参一定要指定类型,有了参数就有了默认的构造方法,object 不可以传参数,如果非要传参数,就会调用相应参数长度的 apply 方法(ps:Trait不可以传参数)。类中的属性默认有getter和setter方法
- 类中重载构造方法时,构造方法中第一行必须先调用默认的构造方法,即 def this(){this(…)}
- Scala中当new class时,类中方法不执行(除了构造方法),其他的都执行
- 在同一个scala文件中,class名称和object名称一样时,这个class叫做这个object的伴生类,这个 object 叫做这个 class 的伴生对象,他们的成员之间可以互相访问私有变量
代码实现
// 如果pname前面写val/var,就相当于公有的,在object外部可以用,而不加val/var就相当于私有的 |
Scala方法与函数
object Lesson_Method { |
容器
Array
import scala.collection.mutable.ArrayBuffer |
List
import scala.collection.mutable.ListBuffer |
Set
import scala.collection.mutable |
Map
import scala.collection.mutable |
Tuple
object TupleLesson { |
继承关系
并行计算
object ParallelLesson { |
Trait
/** |
Match
/** |
PartialFunction
如果一个函数中没有match只有case,可以其定义成PartialFunction(偏函数)。偏函数定义时,不能使用括号传参
/** |
样例类
用关键字case修饰的类叫样例类,它的构造参数默认被声明为val,并且实现了类构造参数的getter方法(因为是val类型参数,所以不能实现setter方法),当构造参数声明为var类型的时候,它将帮你实现setter和getter方法
case class Person1(var name:String, age:Int) |
隐式转换
隐式转换是在Scala编译器进行类型匹配的时候发生。如果找不到合适的类型,那么隐式转换会让编译器在作用范围内自动推导出合适的类型
隐式值&隐式参数
- 隐式值:定义参数的时候,用implicit修饰的变量
隐式参数:方法中用implicit修饰的参数(必须使用柯里化的方式将隐式参数写在方法后面的括号中)
隐式转换作用:当调用方法的时候,不必手动传入方法中的隐式参数,Scala会自动在作用域内寻找隐式值自动传入
/** |
隐式转换函数
隐式转换函数是使用关键字implicit修饰的方法。假如某个A类型变量调用了方法M,但是发现该变量没有方法M,而B类型变量有方法M,那么Scala会在作用域中寻找将A类型转换成B类型的隐式转换函数,如果有这样的隐式转换函数,那么A类型变量就可以调用方法M
/** |
隐式类
使用implicit关键字修饰的类就是隐式类。如果某类型变量A想要调用一些不存在的方法或者变量的时候,可以定义隐式类,然后在隐式类中定义这些方法或者变量,并且在隐式类中传入变量A即可
/** |
ActorModel
ActorModel是用来编写并行计算或分布式系统的,类似于Java的Thread,Actors将状态和行为封装在进程中,不与其他Actors分享状态,当需要和其他Actors交互时通过发送消息,每个Actors都有自己的消息队列
/** |
实现Actor之间的信息传递
object MultiActor { |
补充
通过打电话的例子说明阻塞,非阻塞,同步以及异步的区别
- 阻塞/同步:打一个电话一直到有人接为止
- 非阻塞:打一个电话没人接,每隔5分钟再打一次,直到有人接为止
- 异步:打一个电话没人接,转到语音邮箱留言,然后等待对方回电
Akka 是一个用 Scala 编写的库,是Actor Model的应用,底层实现就是Actor。spark1.6之前,spark分布式节点之间使用Akka传递消息,spark1.6之后使用netty传递消息
文件IO
object FileIOLesson { |