Spark是基于内存的计算框架,它主要包括SparkCore,SparkSQL,SparkML,SparkStreaming等方面的内容,本文从与Strom的区别与联系,基础,算子与这几个方面来介绍SparkStreaming
SparkStreaming简介
SparkStreaming是流式处理框架,7天24小时不间断运行,它支持实时数据流处理,其中实时数据来源可以是Kafka, Flume, Twitter, ZeroMQ或者TCP sockets,它可以使用复杂算子来处理流数据,比如map,reduce,join,window ,最后它还可以将处理后的数据存放在文件系统,数据库以及实时的仪表盘

与Strom的区别与联系
- Storm是纯实时处理数据,SparkStreaming是准实时/微批处理数据,可以通过控制间隔时间做到实时处理,SparkStreaming的吞吐量大
- Storm只能处理简单的汇总型业务,比如累加/累减,而SparkStreaming擅长处理复杂的业务,所以Storm相对于SparkStreaming来讲是轻量级的。SparkStreaming中可以使用Core,SQL或者ML
- Storm的事务机制要比SparkStreaming的要更完善
- Strom和SparkStreaming都支持动态的资源调度
补充
SparkStreaming基础
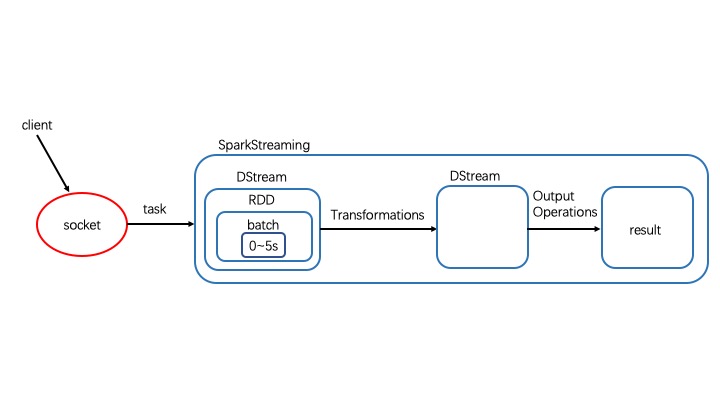
SparkStreaming的底层数据结构是DStream。SparkStreaming启动之后,首先会启动一个job,这个job有一个task来接收数据,task每隔一段时间(batchInterval)会将接收来的数据封装到batch中,每个生成的batch又被封装到一个RDD中,这个RDD又被封装到DStream中,DStream有自己的Transformation类算子(懒执行),需要DStream的outputOperator(action)类算子触发执行。假设batchInterval=5s,如果集群处理一批次的时间是4s,那么0~5s一直接收数据,5~9s一边接收数据一边处理数据,9~10s只是接收数据,每一批次都会造成集群“休息”1s,即集群资源没有充分利用
如果集群处理一批次的时间是9s,那么0~5s一直接收第一批数据,5~10s一边接收第二批数据一边处理第一批数据,10~14s一边接收第三批数据一边处理第一批数据,14~15s一边接收第三批数据一边处理第二批数据,这样数据会越堆越多,如果接收来的数据存入内存会造成oom的问题,如果内存不足放入磁盘,也会加大数据处理的延迟度。所以最理想的状态就是batchInterval=5s,集群处理一批次的时间也是5s
object StreamingApp {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
.setAppName("StreamingTest")
.setMaster("local[2]")
val ssc = new StreamingContext(conf, Durations.seconds(5))
ssc.sparkContext.setLogLevel("Error")
val lines: DStream[String] = ssc.textFileStream("file:///Users/huangning/IdeaProjects/Spark/data")
val words: DStream[String] = lines.flatMap(_.split(" "))
val pairwords: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = pairwords.reduceByKey(_+_)
result.print(100)
result.foreachRDD(pairRDD =>{
println("======Driver端 动态广播黑名单============")
val newRDD: RDD[(String, Int)] = pairRDD.filter(one => {
println("executor in filter ====" + one)
true
})
val result: RDD[Unit] = newRDD.map(one => {
println("executor in map *****" + one)
})
result.count()
})
ssc.start()
ssc.awaitTermination()
ssc.stop(false)
}
}
|
算子
Transfomations
updateStateByKey
ssc.checkpoint("file:///Users/huangning/IdeaProjects/Spark/data/checkpoint")
val result: DStream[(String, Int)] = pariwords.updateStateByKey((currentValues: Seq[Int], preValue: Option[Int]) => {
var totalValue = 0
if (preValue.isDefined) {
totalValue += preValue.get
}
for (value <- currentValues) {
totalValue += value
}
Option(totalValue)
})
|
reduceByKeyAndWindow
val result: DStream[(String, Int)] = pairwords.reduceByKeyAndWindow((v1: Int, v2: Int)=>{v1+v2}, Durations.seconds(15), Durations.seconds(10))
result.print()
ssc.checkpoint("file:///Users/huangning/IdeaProjects/Spark/data/checkpoint")
val result2: DStream[(String, Int)] = pairwords.reduceByKeyAndWindow((v1: Int, v2: Int) => {
v1 + v2
},
(v1: Int, v2: Int) => {
v1 - v2
},
Durations.seconds(15),
Durations.seconds(5))
result2.print()
val result3: DStream[(String, Int)] = pairwords.window(Durations.seconds(15), Durations.seconds(5))
result3.print()
|
val resultDStream: DStream[String] = pairLines.transform((pairRDD: RDD[(String, String)]) => {
println("++++++++++ Driver code +++++++++++++")
val filterRDD: RDD[(String, String)] = pairRDD.filter(tuple => {
val nameList: List[String] = blackList.value
!nameList.contains(tuple._1)
})
val returnRDD: RDD[String] = filterRDD.map(tp => tp._2)
returnRDD
})
|
Output Operations
saveAsTextFile
val lines: DStream[String] = ssc.textFileStream("./data/streamingCopyFile")
val words: DStream[String] = lines.flatMap(line => {
line.split(" ")
})
val pairWords: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = pairWords.reduceByKey((v1: Int, v2: Int) => {
v1 + v2
})
result.saveAsTextFiles("./data/streamingSavePath/prefex", "suffix")
|
print&foreachRDD
result.print(100)
result.foreachRDD(pairRDD =>{
println("======Driver端 动态广播黑名单============")
val newRDD: RDD[(String, Int)] = pairRDD.filter(one => {
println("executor in filter ====" + one)
true
})
val result: RDD[Unit] = newRDD.map(one => {
println("executor in map *****" + one)
})
result.count()
})
|
补充
RDD中的许多Actions变成了sparkStreaming中的Transfomations,比如count,reduce,countByValue
Driver HA
object SparkStreamingDriverHA {
val checkpointDir = "./data/streamingCheckpoint"
def main(args: Array[String]): Unit = {
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointDir, CreateStreamingContext)
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
def CreateStreamingContext(): StreamingContext = {
println("===========Create new StreamingContext=========")
val conf: SparkConf = new SparkConf().setAppName("DriverHA").setMaster("local")
val ssc = new StreamingContext(conf, Durations.seconds(5))
ssc.sparkContext.setLogLevel("Error")
ssc.checkpoint(checkpointDir)
val result: DStream[(String, Int)] = ssc.textFileStream("./data/streamingCopyFile")
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
result.print(2)
result.foreachRDD(pairRDD => {
val value: RDD[(String, Int)] = pairRDD.filter(one => {
println(" ************* filter ***********")
true
})
value.foreach(println)
})
ssc
}
}
|
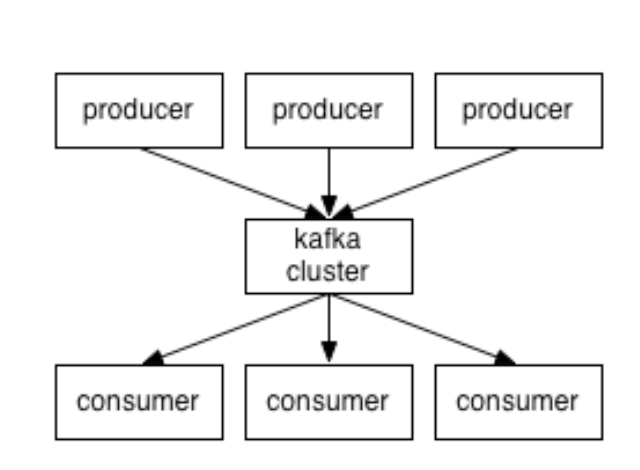
Kafka
Kafka是高吞吐量(因为有零拷贝)的分布式消息系统
定义
producer
消息生产者,用来生产数据,producer自己决定往哪个partition写消息,写消息存在两种机制,可以是轮询的负载均衡,也可以是基于hash来写入partition(基于 key hash的时候,如果 key 为 null,则执行轮询)。partition内部是FIFO的,partition之间不一定是FIFO的,但是如果我们把topic设为一个partition,这样就是严格的FIFO
consumer
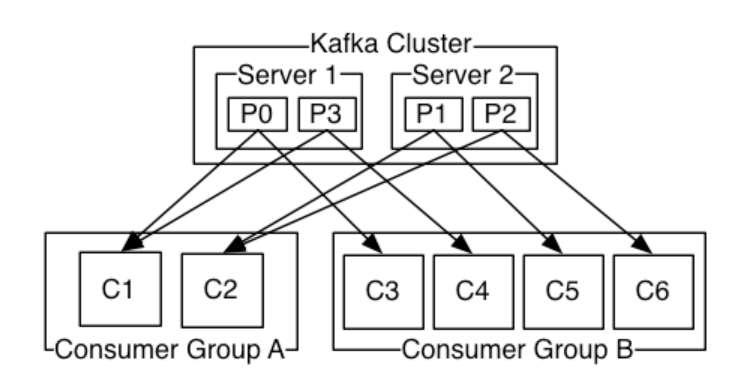
consumer是消息消费者,用来消费数据,每个consumer都有对应的group(比如下图中的groupA中有两个consumer),各个group独立消费互不影响。同一个topic中的数据对于同一组只能被消费一次,每个cousumer消费不同的partition。版本0.8之前由consumer自己维护消费到哪个offset,0.8之后由zookeeper管理
broker
broker是kafka集群的server,本质上就是一台kafka节点。每一个partition都属于一个broker,一个broker可以lead多个partition,比如:一个topic里面有6个parititon,有两个broker,那么每个broker就管理三个partition。broker负责消息的读写请求,存储消息,没有主从关系,依赖zookeeper
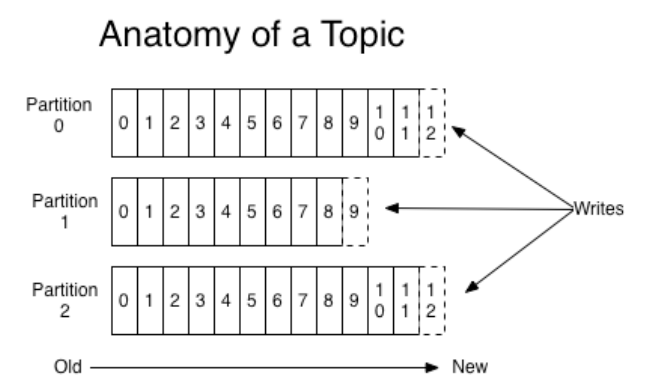
paritition
partition可以简单地想象为一个文件,当数据发过来的时候就往这个partition上面append,每个partition内部消息严格遵循FIFO强有序,其中的每个消息都有一个序号叫offset,它是构成topic的基本单元,partitiion有以下特点:
- 可以指定消息队列,在创建topic的时候创建,并可以指定副本数
- 消息不存储在内存,而是直接写入磁盘文件
- 其中的消息默认一周删除,而不是消费完就删除(这也是kafka与其他的消息系统不同之处,kafka不存在消费完的概念,之后过期的概念)
topic
kafka里面的消息是由topic来组织的,可以将其想象为一个队列,一个队列就是一个topic,然后每个topic又分成了多个parititon为了做并行的计算,每个
partition里面的消息是有序的,相当于是有序队列
zookeeper
管理broker,存储broker,partitioned信息
零拷贝
零拷贝指cpu不需要为数据在内存之间的拷贝消耗资源,通常指在网络上发送文件不需要现将文件内容拷贝到用户空间(user space),而是直接在内核空间(kernel space)中传输到网络的方式
- 非零拷贝图示
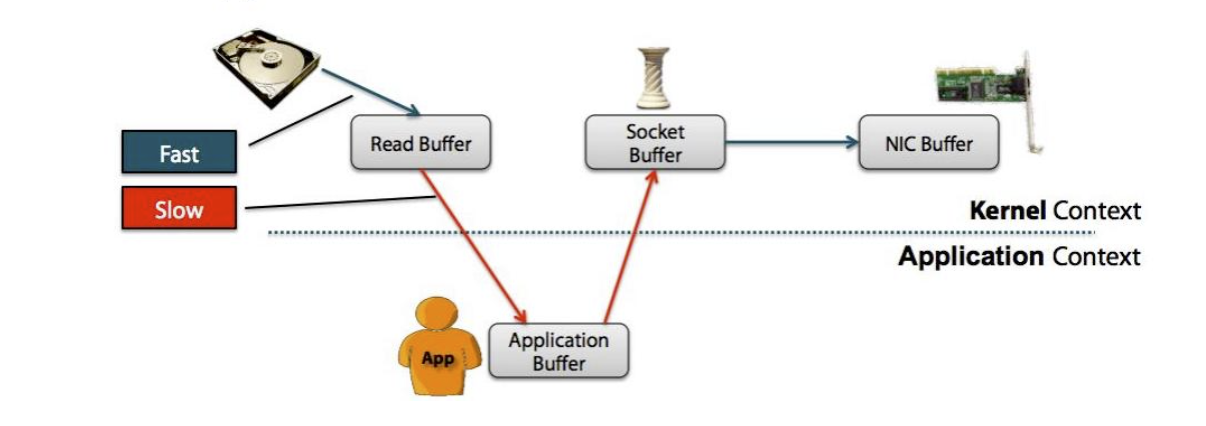
- 零拷贝图示
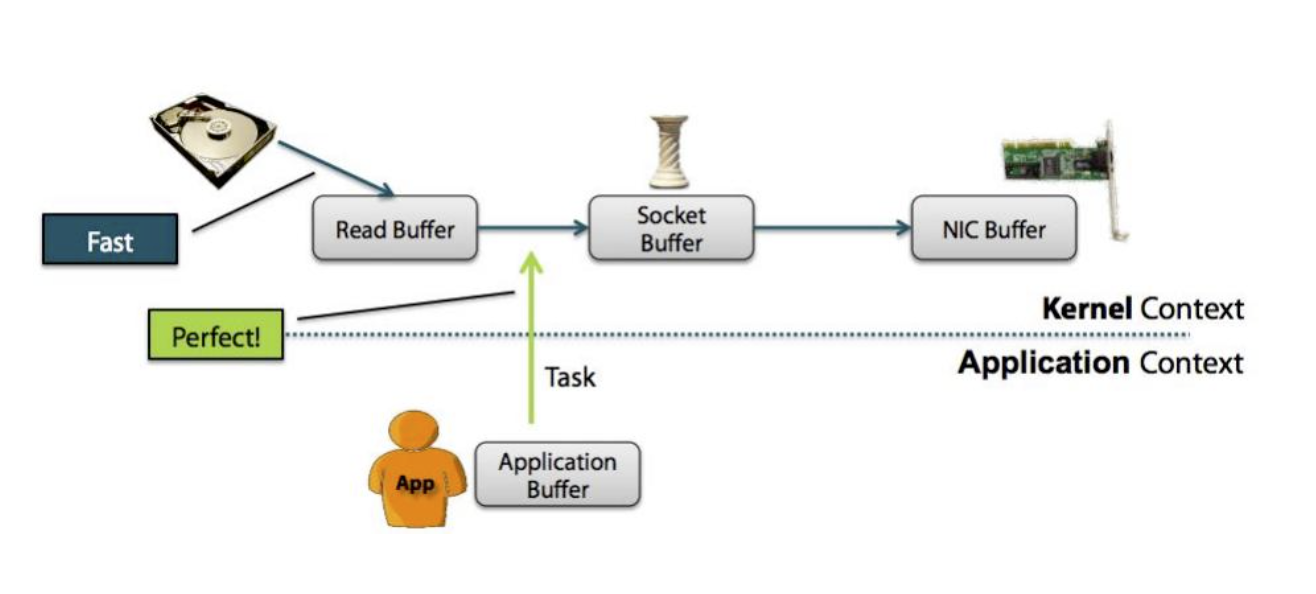
特点
- 是一个生产者消费者模型,有FIFO(在topic里面)
- 高性能,比如单节点支持上千个客户端,百MB/s吞吐
- 持久性,比如消息直接持久化在普通磁盘上且可以保证顺序写顺序读
- 分布式,可以构建数据副本,因为有数据副本同一份数据可以到不同的broker上面去, 如果磁盘坏掉的时候,数据不会丢失,比如构建3个副本, 就是在3个机器磁盘都坏掉的情况下数据才会丢
- 不丢数据,producer将数据存入磁盘
- 反复消费数据(数据存7天)
- kafka与spark streaming的结合中,后者扮演consumer的角色