Hadoop是由Common,HDFS,YARN,MapReduce以及Ozone这些模块构成的开源软件,和其他相关项目,比如Spark,Hive以及HBase等统一称为Hadoop生态系统,本文主要介绍从存储模型,架构模型,版本区别以及集群搭建来介绍Hadoop
存储模型
HDFS
化整为零,并行计算的思想决定了Hadoop的存储模型——HDFS(Hadoop Distributed File System,分布式文件系统),化整为零指将大文件分成许多小文件HDFS,即分布式文件系统,并行计算指将多个小文件发送到多台服务器同时进行计算
服务器
塔式服务器
台式计算机是由机箱和显示器组成,去掉显示器的机箱就叫做塔式服务器(Tower Server)

机架服务器
放在柜子里面的服务器扁平类型的服务器叫机架服务器(Rack Server),也叫机柜服务器,一般一个机柜里面可以放16到32个机架服务器

刀片服务器
由一条条主板和位于底侧的母板构成的服务器叫刀片服务器(Blade Server),其中主板上布有cpu和内存;刀片服务器的成本虽然高,但是算力强,可以作为单点服务器

Block
将文件上传HDFS的时候会被分割成多个Block并均匀地分散到各个服务器上,假设有10个Block,那么如果10个服务器,每个Block就会分别上传到一台服务器上,如果有5台服务器,那么每两个Block就会传到一台服务器上。Block的发送是无序的,每个Block默认大小是128M
分割
上传文件变成为二进制并按照字节进行线性分割成大小一致的Block,但是针对占3个字节的utf-8编码的汉字可能会造成部分切割的问题,但是hadoop已将该问题解决,同一个文件被切成的多个Block大小一致,但多个文件之间的Block大小以及Block个数可能不一致
副本
每个Block默认有3个副本,Block副本有两种分配策略
如果在DataNode上传文件,会在该节点创建第一个副本,然后在与第一个副本不同机柜的某个服务器创建第二
个副本,然后在与第二个副本同一个机柜的不同服务器上创建第三个副本,如果
若上传的客户端不再集群节点上,那上传之后会找一个服务器存放第一个副本,然后在与第一个副本不同机柜的某个服务器创建第二
个副本,然后在与第二个副本同一个机柜的不同服务器上创建第三个副本,如果
注:每个服务器上的副本个数最多为1
补充
HDFS中的文件不可修改,因为每个Block都有相应的偏移量,如果修改其中某个Block,就会发生蝴蝶效应,即其相邻的block以及其他block的偏移量都需要进行修改,进而需要将整个集群进行修改。但是可以对HDFS进行append操作来保持之前数据的一致性

架构模型
文件数据分为元数据(描述数据的数据)和数据本身,由于大量的数据需要一次写入多次读取,因此为了更加快速高效地查询数据,产生了Hadoop的主从架构模型,接下来分六点分别介绍主从节点以及之间的关系
- NameNode节点(主节点)是单节点,负责保存元数据,
- DataNode节点(从节点)是多节点,负责存储block数据
- NameNode与DataNode要保持心跳,即DataNode动态统计上传给NameNode可用的block列表信息
- HDFS Client与NameNode交互元数据信息,比如要存储文件的时候,需要判断存储路径是否存在,如果不存在需要新建路径,再比如要查询文件的时候需要确认文件在哪些节点上
- HDFS Client与DataNode交互文件block数据
- DataNode利用服务器本地文件系统直接存储block,即将block转成文件存储在某个目录直线,可以看出HDFS的所用成本很低
3.x与2.x的区别
- classpath隔离,不会造成不同版本的jar包冲突
- 支持hdfs的擦除编码(erasure encoding),进而节省了50%的空间
- datanode内部新增负载均衡,比如新增datenode之后,其余datenode会将部分数据导入新增的datenode之中
- shell重写,3.x与2.x有三分之一的区别,并且大部分区别都在shell重写
- mr支持内内存参数推断
- cgroup将内存和磁盘隔离(dock就是cgroup和namespace的二次开发)
集群搭建
伪分布式
Step1. 安装jdk1.8
Step2. 在/usr/hadoop-3.1.4/etc/hadoop/hadoop-env.sh的末尾新增环境变量以及节点启动用户
集群启动之后会从该脚本下寻找java环境变量,而不是/etc/profile |
Step3. 在/usr/hadoop-3.1.4/etc/hadoop/core-site.sh中配置NameNode节点,元数据以及block数据保存路径
<configuration> |
Step4. 在/usr/hadoop-3.1.4/etc/hadoop/hdfs-site.sh中配置SecondaryNameNode以及副本信息
<configuration> |
Step5. 在/usr/hadoop-3.1.4/etc/hadoop/workers中配置从节点信息,相当于Hadoop2.x中的slaves
node01 |
Step6. 在/usr/hadoop-3.1.4格式化namenode并启动
# 格式化namenode之后会在 hadoop.tmp.dir/dfs/name/current下面产生四个文件,其中有两个image文件以及1个VERSION文件,VERSION里面包含了集群的唯一编号clusterID |
Step7. 在本地浏览器通过node01:9870访问NameNode信息
# 如果忘记端口号,可以通过下述命令查看监听的端口信息 |
全分布式
假设现在有4个节点,每个节点的角色如下
| NameNode | SecondaryNameNode | DataNode | |
|---|---|---|---|
| node01 | ✔︎ | ||
| node02 | ✔︎ | ✔︎ | |
| node03 | ✔︎ | ||
| node04 | ✔︎ |
Step1. 在4个节点上安装jdk1.8
Step2. 在/usr/hadoop-3.1.4/etc/hadoop/hadoop-env.sh的末尾新增环境变量以及节点启动用户
集群启动之后会从该脚本下寻找java环境变量,而不是/etc/profile |
Step3. 在/usr/hadoop-3.1.4/etc/hadoop/core-site.sh中配置namenode节点,元数据以及Block数据保存路径
<configuration> |
Step4. 在/usr/hadoop-3.1.4/etc/hadoop/hdfs-site.sh中配置SecondaryNameNode以及副本信息,其中SecondaryNameNode的作用是负责文件合并以及持久化,并不是namenode的备用节点
<configuration> |
Step5. 在/usr/hadoop-3.1.4/etc/hadoop/workers中配置从节点信息,相当于Hadoop2.x中的slaves
node02 |
Step6. 在/etc/profile修改环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step7. 在/usr下将配置分发到其他节点
scp /usr/hadoop-3.1.4 node02:`pwd` |
Step8. 在所有节点执行环境变量
source /etc/profile |
Step9. 在node01上格式化namenode并启动集群
hdfs namenode -format |
Step10. 在本地浏览器通过node01:9870访问namenode信息
# 如果忘记端口号,可以通过下述命令查看监听的端口信息 |
联邦
为了解决NameNode存储瓶颈问题,提出了联邦(Fedration)的思想,即多个NameNode之间相互独立,底层共用一套DataNode集。但通过指定NameNode进行了数据存储,后期只能从该NameNode进行数据查询,因此会造成NameNode指定错误的问题,大公司为了解决该问题一般会在上方搭建一个文件系统(目录树),每个目录/接口都与底层的指定的NameNode或HBSE(当数据仅仅用来存储)对应
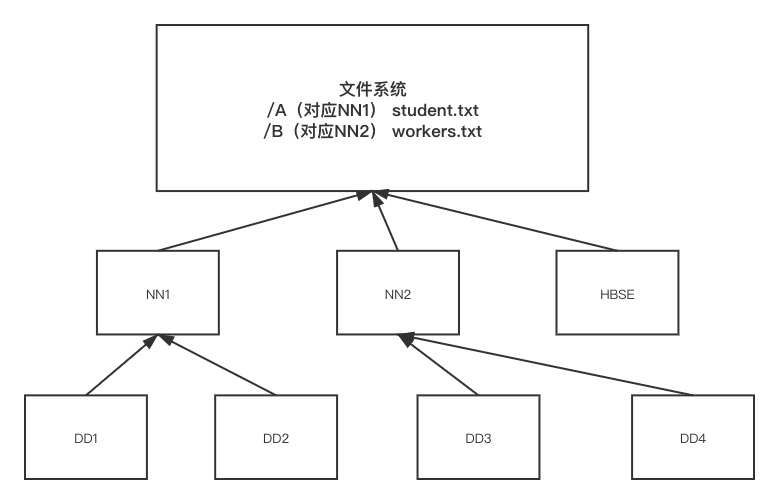
联邦虽然解决了NameNode存储瓶颈问题并实现了扩展性,但仍然无法解决NameNode单点故障转移的问题,即其中一个NameNode挂掉了,就无法找到相应DataNode信息的问题
高可用
假设现在有4个节点,每个节点的角色如下
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | |
|---|---|---|---|---|---|---|
| node01 | ✔︎ | ✔︎ | ✔︎ | |||
| node02 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | |
| node03 | ✔︎ | ✔︎ | ✔︎ | |||
| node04 | ✔︎ | ✔︎ |
Step1. 在4个节点上安装jdk1.8
Step2. 在/usr/hadoop-3.1.4/etc/hadoop/hadoop-env.sh的末尾新增环境变量以及节点启动用户
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step3. 在/usr/hadoop-3.1.4/etc/hadoop/hdfs-site.sh配置其他节点的角色信息
<configuration> |
Step4. 在/usr/hadoop-3.1.4/etc/hadoop/core-site.sh中配置NameNode节点,元数据,Block数据保存路径以及Zookeeper与客户端通信的节点信息
<configuration> |
Step5. 假设之前在4个节点搭建过全分布式,那么直接在node01中/usr/hadoop-3.1.4/etc/hadoop/下将修改过的配置分发到其余3个节点
scp hadoop-env.sh core-site.xml hdfs-site.xml node02:`pwd` |
Step6. 在node02,node03,node04上搭建zookeeper集群,其中zookeeper集群与hadoop集群是相互独立的
Step6.1. 在node02上安装zookeeper3.4.6,并在/etc/profile配置环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step6.2. 将配置好的环境变量发送到其他节点上并执行
scp /etc/profile node02:/etc/profile |
Step6.3. 在node02上将/usr/zookeeper-3.4.6/conf/zoo_sample.cfg重命名为/usr/zookeeper-3.4.6/conf/zoo.cfg,并修改
dataDir=/var/zk |
Step6.4. 在node02的/usr/下将配置好的zookeeper分发到其余节点
scp zookeeper-3.4.6 node03:`pwd` |
Step6.5. 根据之前的/usr/zookeeper-3.4.6/conf/zoo.cfg的配置信息在搭建zookeeper的3个节点上分别增加服务器编号文件
# node02 |
Step6.6. 分别在node02,node03,node04上启动zookeeper集群
# 启动集群 |
补充
1) zookeeper启动遵从过半机制,即启动zookeeper服务器个数超过搭建zookeeper服务器个数的一半才可以正常启动zookeeper集群
2) 可以通过zkCli.sh来启动客户端进而对zookeeper集群进行修改,但一般是在namenode在进行状态切换的时候会对zookeeper进行修改
3) zookeeperyou选举机制,一般是根据服务器编号或者启动顺序来决定搭建zookeeper的服务器是follower还是leader
Step7. 在node01,node02,node03上分别启动jounalnode
# 可以通过jps查看node01,node02,node03的JNN是否启动 |
Step8. namenode同步透穿
Step8.1. 在node01上格式化namenode并启动namenode
# 也可以在namenode2上格式化namenode,但只能格式化一个namenode,另一个namenode需要通过JNN同步透穿来作standby角色 |
Step8.2. 在node02上同步node01上的namenode信息
hdfs namenode -bootstrapStandby |
Step9. 格式化zookeeper
# 在zookeeper创建一个2级的注册目录/mycluster/hadoop-ha,将要保存各个nanmenode节点信息 |
Step10. 测试主备namenode节点切换
Step10.1. 在node01关闭active状态的namenode
hdfs --daemon stop namenode |
通过node01:9870查看node01挂掉,通过node02:9870查看node02的状态变成active,通过zkCli.sh进入客户端,查询mycluster/hadoop-ha可以查看到两个节点的状态
在node01上重启namenode
hdfs --daemon start namenode |
通过node01:9870查看node01变成了standby,通过node02:9870查看node02的状态变成active
Step10.2. 关闭node02的zkfc进程
hdfs --daemon stop zkfc |
通过node01:9870查看node01变成了active,通过node02:9870查看node02的状态变成standby
补充
脑裂(brain-split):处于active状态的namenode挂掉/假死状态的时候,另外一个那么node启动,过段时间挂掉/假死状态的namenode重新启动导致两个active状态的namenode同时工作的现象较脑裂
解决脑裂方法
使用sshfence隔离机制,即active的namenode假死之后,zkfc进程向zookeeper写入异常,standby的namenode上zkfc从zookeeper读入异常后就会通过ssh连接挂掉的active状态的namenode并将其kill掉(但显然如果真挂掉的话是连接不上的),如果收到成功kill的信息,当前standby的namenode状态就会切换到active,如果经过一段时间都没有收到kill执行成功的信息,那么当前standby的namenode就会执行自定义脚本,但是该方法导致了active的namenode挂掉之后,standby状态的namenode没有马上升级为active状态,解决该问题的办法就是在在
/usr/hadoop-3.1.4/etc/hadoop/hdfs-site.sh中修改dfs.ha.fencing.methods<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
Step11. 在node01上启动HA集群
start-dfs.sh |