说在前面的话
由于Hadoop开发难度较高,并且非Java程序员有对HDFS的数据做MapReduce操作的需求,Hive应运而生。本文主要从简介,架构,搭建,运行方式以及HiveSQL来介绍Hive
Hive简介
Hive是数据仓库,数据仓库不等于数据库,数据仓库是用来对历史数据进行分析但不支持实时查询,而数据库主要是用来实时查询但不支持不支持大数据分析
Hive架构
- 基于HDFS存储数据
- 基于MySQL存储元数据
因为HDFS中的文件没有格式信息,所以将元数据单独存在MySQL中 - 支持客户端访问并且将SQL语句转成HDFS操作或者MapReduce作业
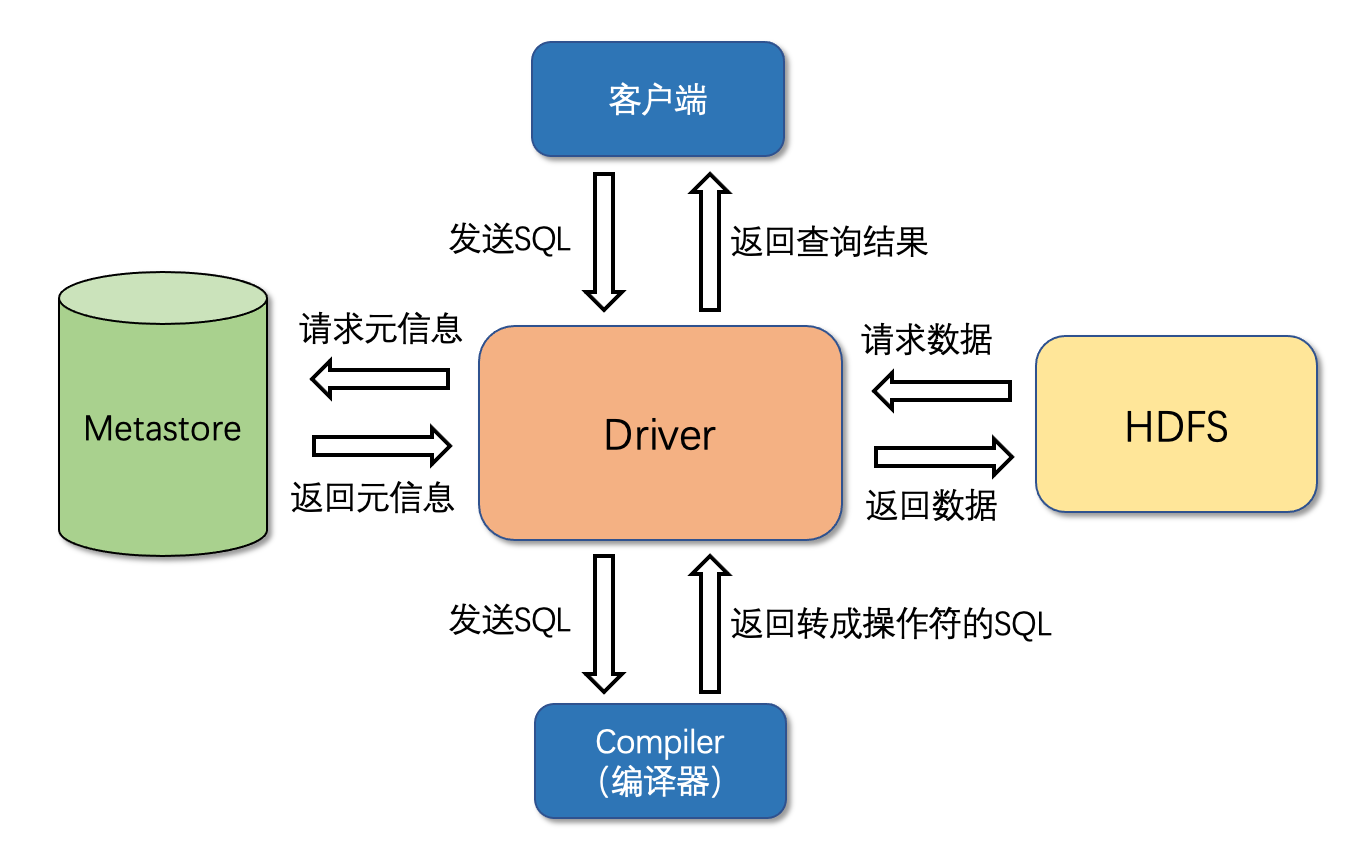
其中编译器将Hive SQL转换成操作符,比如Select操作符,Limit操作符以及FileOutput操作符,操作符是Hive的最小处理单元,每个操作符代表HDFS一个操作或一道MapReduce作业
Hive搭建
根据对MySQL访问方式的不同,Hive有三种搭建模式:本地模式,单用户模式以及多用户模式,其中本地模式使用位于内存的derby数据库,平时几乎不用,本文只介绍单用户模式以及多用户模式
单用户模式
| Mysql | Hive | |
|---|---|---|
| node01 | ✔︎ | |
| node02 | ✔︎ |
MySQL配置
Step1. yum安装包更新
yum update |
Step2. 更换安装镜像
# 安装wget |
Step3. 安装MySQL
Linux系统安装软件共有4种方法,分别是yum,rpm,源码安装以及压缩包安装,本文使用yum安装。安装时候不要只写mysql,否则仅仅仅安装了客户端,这里安装mysql-server是为了供其他服务器访问
yum install -y mysql-server |
Step4. 登陆MySQL
# 启动mysql服务器 |
Step5. 查看用户权限表mysql
use mysql; |
Step6. 修改用户权限表
# 授予密码123,用户名为root的权限 |
Step7. 重新登陆MySQL
# 退出mysql |
其中在mysql里面的hive_remote库的TBLS表记录的Hive所有的元数据
Hive配置
Step1. 下载apache-hive-3.1.2-bin.tar.gz以及mysql-connector-java-5.1.32.jar,发送到node02,并进行解压
tar apache-hive-3.1.2-bin.tar.gz -C /usr/ |
Step2. 在/etc/profile配置环境变量
export HIVE_HOME=/usr/apache-hive-3.1.2-bin |
Step3. 在node02中/usr/apache-hive-3.1.2-bin/conf修改文件名称
mv hive-default.xml.template hive-site.xml |
Step4. 修改配置文件hive-site.xml内容
首先将配置文件中configuration内容删掉,可以通过末行模式下的命令:.,$-1d,将光标所在行及以下至倒数第二行删除掉
<configuration> |
Step5.将jdbc驱动文件移动到Hive指定位置
mv /root/mysql-connector-java-5.1.32.jar /usr/apache-hive-3.1.2-bin/lib |
Step6. 将Hive中的jline移动到Hadoop指定位置,替换掉Hadoop相应的旧版本jar包
mv /usr/apache-hive-3.1.2-bin/lib/jline-2.12.jar /usr/hadoop-3.1.4/share/hadoop/yarn/lib |
Step7. 将Hadoop中guava-27.0-jre.jar包移动到Hive指定位置,替换掉Hive相应的旧版本jar包
mv /usr/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /usr/apache-hive-3.1.2-bin/lib |
Step8. 初始化元数据
/usr/apache-hive-3.1.2-bin/bin/schematool -dbType mysql -initSchema |
Step9. 启动hive客户端
hive |
多用户模式
| MySQL服务端 | Hive服务端 | Hive客户端 | |
|---|---|---|---|
| node01 | ✔︎ | ||
| node03 | ✔︎ | ||
| node04 | ✔︎ |
MySQL配置与单用户模式配置方式相同,这里不再赘述
Hive配置
Step1. 下载apache-hive-3.1.2-bin.tar.gz以及mysql-connector-java-5.1.32.jar,发送到node03和node04,并进行解压
tar apache-hive-3.1.2-bin.tar.gz -C /usr/ |
Step2. 在node03和node04的/etc/profile配置环境变量
export HIVE_HOME=/usr/apache-hive-3.1.2-bin |
Step3. 修改node03和node04的配置文件hive-default.xml.template名称
cd /usr/apache-hive-3.1.2-bin/conf |
Step4. 修改node03和node04配置文件hive-site.xml内容
<!-- node03配置--> |
Step5. 在node03和node04上将Hadoop中guava-27.0-jre.jar包移动到Hive指定位置,替换掉Hive相应的旧版本jar包
mv /usr/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /usr/apache-hive-3.1.2-bin/lib |
Step6. 在node03上将jdbc驱动文件移动到Hive指定位置
mv /root/mysql-connector-java-5.1.32.jar /usr/apache-hive-3.1.2-bin/lib |
Step7. 在node04上将Hive中的jline移动到Hadoop指定位置,替换掉Hadoop相应的旧版本jar包
# 谁需要请求metastore server谁就需要把jline进行替换 |
Step8. 在node03启动Hive服务端
# 启动后会发生阻塞,因为有端口是9083的客户端正在监听它 |
Step9. 在node04启动hive客户端
hive |
Hive运行方式
命令行运行
hive
Step1. 启动 metastore server
hive --service metastore |
Step2. 启动hive
hive |
如果无法正常启动,存在以下两种可能:首先检查NameNode,可以检查是否存在active状态的namenode,其次是之前启动过metastore server但是忘记关闭,可以通过ss -nal来查看占用9083端口的pid,然后通过kill -9 pid杀掉对应的进程后再其次通过hive --service metastore来启动服务
# 在hive客户端中可以和hdfs直接交互,比如查询hdfs的某个文件信息 |
beeline
Step1. 在node03启动hiveserver2
hiveserver2 |
Step2. 在node04通过beeline连接hiveserver2
# hive默认用户名及密码不验证, 但hive支持密码验证 |
Step2也可以拆成2步执行
# step2.1 |
使用beeline所有操作命令都需要加前缀 !, 比如退出命令
!quit |
当用beeline登录hive时候root没有权限的解决办法,可以通过在/usr/hadoop-3.1.4/etc/hadoop/core-site.xml中新增配置
<property> |
其中root就是通过beeline访问的时候-n后面的名字。重启HDFS,再次启动hiveserver2和beeline就不会报错啦~
切记!!!一定要在HDFS启动后再启动Hive服务,如果启动HDFS之前就启动了Hive,需要关闭Hive以及HDFS,重新启动HDFS后,再启动Hive服务
脚本运行
通过编写脚本来运行在实际生产环境中用的最多,比如通过 Java 配置定时任务
# 未进入客户端直接执行hive |
JDBC运行
Step1. 启动hiveserver2
Step2. 编写 Java 连接 Hive
import java.sql.*; |
HiveSQL
HiveSQL分成DDL,DML以及DCL,对应的用法可以参考Hive官网 的Documentation —> Language Manaual
DDL
创建/删除库
# 创建表 |
创建/删除表
hive> CREATE TABLE psn( |
其中 MySQL 中 CREATE TABLE TABEL_NAME 已经完成了创建表操作,而 Hive 还需要声明数据输出格式,因为Hive的数据存在HDFS上,存在HDFS上的都是文件是没有格式,所以用HIVE创建表的时候需要写好解析模式(类似正则化规则匹配),使得查询数据时有格式的输出
Serde建表
hive> CREATE TABLE logtbl( |
其中log.txt文件内容如下
192.168.57.4 - - [29/Feb/2016:18:14 +0800] "GET /bg-upper.png HTTP/1.1" 304 - |
但Serde用法比较复杂,大部分场景不会用到哒~
内部和外部表
# 内部表 |
内部表和外部表的区别
- 外部表需要给定 HDFS 路径,即需要手动维护,而内部表不需要,因为Hive自动维护表
- 删除表时外部表只将元数据删除而不删除存储数据,内部表将元数据和存储数据全部删除
DML
数据导入表
将数据导入Hive表有4种方法
Load方法
将文件Load方法进表格,相比于传统的insert的优点是可以批量插入数据,如果导入时加LOCAL,此时的LOAD是将本地文件copy并上传到HDFS指定目录,如果不加LOCAL,此时的LOAD是将HDFS上的某个文件直接mv到HDFS指定目录
hive> LOAD DATA LOCAL INPATH '/root/data' INTO TABLE psn; |
HDFS上传
通过HDFS将数据直接上传到指定路径
hdfs dfs -put '/root/data' /user/hive_remote/warehouse/psn |
Insert table
通过查询语句来插入数据,可以用来批量插入多张表,使用场景一般是复制表,或者导出中间表,即存放中间计算结果的数据表
hive> FROM psn |
Inserting values
用SQL语句向表格中插入values,本质是跑MapReduce任务,用起来最麻烦,小编不建议用这种方法哦🙅🏻♂️
hive> INSERT INTO TABLE psn VALUES |
其中用到的测试数据data为👇
1,小明1,lol-book-movie,beijing:shangxuetang-shanghai:pudong,175-75-man |
补充
- MySQL 有写检查,即格式不匹配不能写入,但是Hive没有写检查,只有读检查,如果用Hive查询的时候匹配不上的字段会显示null。不做写检查的原因是在大数据场景下,写检查代价比较大,比如上传一个特别大的文件,写了一半发现有不符合条件的数据,最好的策略就是直接忽略而不是回滚
- 文件都是通过地址直接访问,磁盘上文件保存的位置不会随着复制或者移动而发生变化,比如:DataNode 就是块硬盘,在上面移动文件只会改变其索引,而复制是在磁盘上产生额外的拷贝数据,所以移动比复制快
查询表
# 查看表的结构信息 |