说在前面的话
HBase源于Google发表的论文BigTable,它与另外两篇GFS以及MapReduce并称为“三驾马车”。本文从简介,架构,数据模型,架构,搭建以及应用来介绍HBase
Hbase简介
HBase是利用HDFS作为文件存储系统,利用MapReduce处理海量数据,利用Zookeeper作为分布式协同服务的非关系型数据库,它主要用来存储非结构化和半结构化的松散数据。HBase是具有高可靠(依托于Hadoop),高性能(MapReduce可以处理海量数据),面向列(列数据库是按列存储,即不用预先声明字段,而是添加数据的时候再定义字段,而MySQL是列都定义好的以行为单位的数据库,有数据缺失时就用Null占内存),可伸缩(Hadoop集群可以扩展节点)以及实时读写(将数据实时读写到内存里)的分布式数据库
HBase数据模型
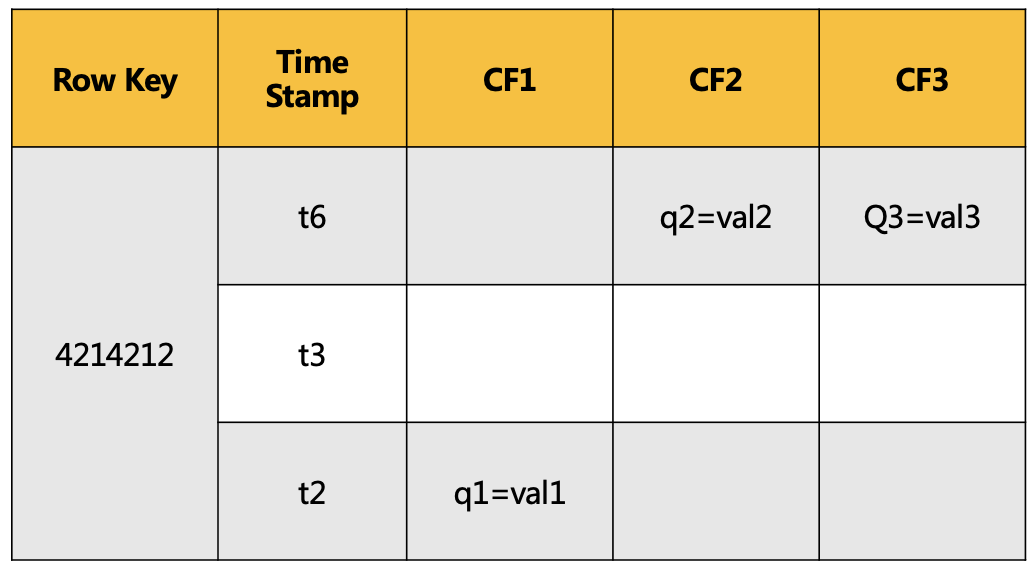
上图代表了HBase的某条数据。可以通过Row key+ 列族 + 列名确定某个单元格,每个单元格都有对应的时间戳,单元格内部是未解析的字节数组。在更新数据方面,MySQL是新数据直接覆盖旧数据,而HBase是插入新数据,老数据保留并标记失效,在merge阶段进行删除,老数据可通过时间戳读取,比如:在CF2里更新了q1=val2,那么之前的q1=val1会标记失效
HBase架构
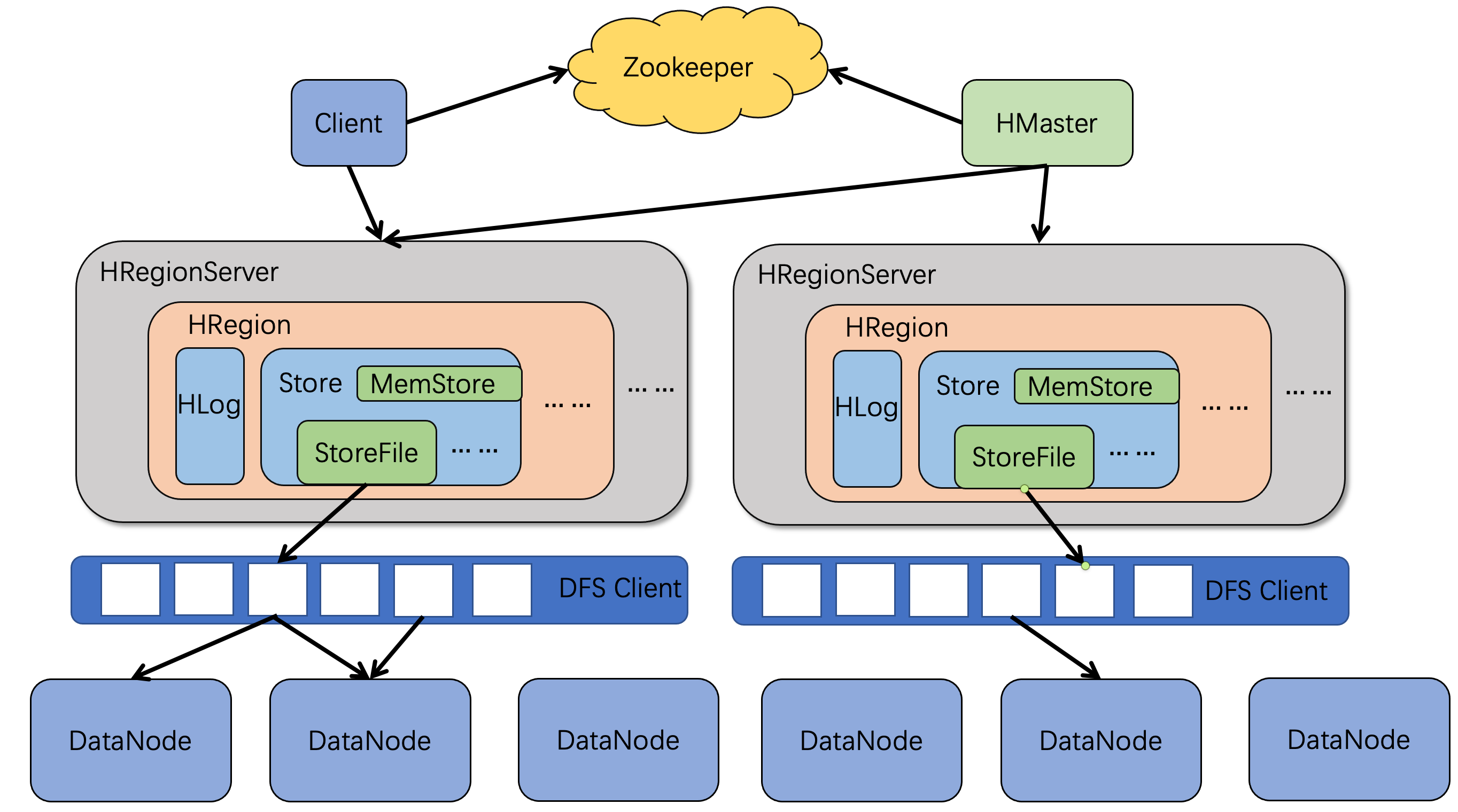
Client
Client负责访问HBase并维护加快对HBase的访问的memcache。访问Hbase数据的顺序是一级缓存,二级缓存数据库。HBase中的MemStore,除了用来写缓存,也可以分担部分读缓存的压力,比如当查询数据时,先在MemStore寻找,找不到再在StoreFile里寻找
Zookeeper
Zookeeper主要起到了高可用以及记录数据的作用,高可用体现在它保证任何时候集群中只有一个HMaster,实时监控RegionServer的上线和下线信息,并实时通知HMaster,比如:心跳检测时,有个RegionServer宕掉了可以及时通知HMaster,记录数据体现在它存储Hbase的schema和table的元数据,除此之外它还存储所有Region的寻址入口
RegionServer
RegionServer负责维护HRegion,比如:对Region IO请求的处理、切分逐渐变大的Region
Region
每张表初始只有一个Region,随着数据的不断插入,Region会不断增大,当达到阈值时HBase自动将其等分成两个新的Region,以此类推,最后一张表就会被存储到多个Region上,其中每个Region保存表里某段连续的数据
Store
一个Region由多个Store组成,一个Store对应一个列族。Store包含位于内存的MemStore和位于磁盘的StoreFile。Hbase进行写操作时先写入MemStore,当达到阈值时HRegionServer启动flashcache进程将MemStore中的数据刷入StoreFile,每次自动刷入都会形成大小相同的StoreFile;当StoreFile数量达到阈值时,系统会进行minor合并,比如每次合并两个StoreFile,在合并过程中会进行版本合并以及删除工作,其中合并方式还有major,即将所有文件合并成一个大文件,该机制不会自动触发,通常是写个脚本让其凌晨执行;当Region里StoreFile的大小以及数量超过阈值后,比如Region存储大小超过128M后会把当前的Region均匀分割为两个,并由HMaster分配到指定的Regionserver来实现负载均衡
HLog
HLog是WAL,原始日志只有保存操作,而HLog不仅可以保存日志,还可以保存数据。Hlog文件是普通的Hadoop Sequence File,其中Key是HlogKey对象,它记录了写入数据的归属信息,比如table名,region名以及timestamp等
该架构还存在一些问题,比如StoreFile小文件的产生会导致资源分配和任务调度耗时长,再比如数据倾斜导致HRegionServer1特别忙,HRegionServer2特别闲进而造成负载不均衡
HBase搭建
伪分布式
Step1. 安装jdk1.8
Step2. 下载hbase-0.98.12-hadoop2-bin.tar.gz, 发送到节点node04并进行解压
tar -zxvf hbase-0.98.12-hadoop2-bin.tar.gz -C /usr/ |
Step3. 配置环境变量/etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step4. 在/usr/hbase-0.98.12-hadoop2/conf/hbase-env.sh中新增配置
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step5. 在/usr/hbase-0.98.12-hadoop2/conf/hbase-site.xml添加HBase以及ZooKeeper数据的存储路径
<configuration> |
Step6. 启动HBase服务
# 启动之前最好关闭其他的Java进程 |
出现下图就表示HBase启动成功啦 🥳

Step7. 进入Hbase客户端
hbase shell |
全分布式
| NameNode | DataNode | ZK | HMaster | HRegionServer | |
|---|---|---|---|---|---|
| node01 | ✔︎ | ✔︎ | |||
| node02 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | |
| node03 | ✔︎ | ✔︎ | ✔︎ | ||
| node04 | ✔︎ | ✔︎ | ✔︎ | ||
| node05 | ✔︎ |
Step1. 安装jdk1.8
Step2. 时间同步
通过date查看各个节点的时间是否相同,如果不相同需要下载时间服务器插件
yum install -y ntp |
然后在各个节点上同步时间
ntpdate ntp1.aliyun.com |
Step3. 配置node05的密钥登录
相比Hadoop高可用搭建的节点而言,这里需要额外增加一台节点node05并需要彼此免密钥登录
# 在node05上通过下述快捷命令产生密钥 |
Step4. 启动HDFS
HBase的数据文件需要保存到HDFS上
start-dfs.sh |
Step5.下载hbase-0.98.12-hadoop2-bin.tar.gz,发送到node01并解压
tar -zxvf hbase-0.98.12-hadoop2-bin.tar.gz -C /usr/ |
Step6. 配置环境变量/etc/profile,发送到node02,node03,node04,node05并source
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
其中,从Hadoop高可用搭建过程可知ZOOKEEPER_HOME配置只在node02,node03,node04存在,node01不需要该配置
Step7. 在/usr/hbase-0.98.12-hadoop2/conf/hbase-env.sh中新增配置
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step8. 在/usr/hbase-0.98.12-hadoop2/conf/hbase-site.xml添加HBase数据以及ZooKeeper数据的存储路径
<configuration> |
其中hbase.rootdir中mycluster来自于Hadoop配置文件hdfs-site.xml中的dfs.nameservices名
Step9. 在/usr/hbase-0.98.12-hadoop2/conf/regionservers添加HRegionServer节点
node02 |
Step10. 在/usr/hbase-0.98.12-hadoop2/conf/backup-masters配置备用节点
node05 |
Step11. 将hadoop的配置文件hdfs-site.xml拷贝到HBase的配置文件中
cp /usr/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /usr/hbase-0.98.12-hadoop2/conf |
Step12. 将配置信息分发到其他节点
scp -r hbase-0.98.12-hadoop2/ root@node01:/usr |
Step12. 启动HBase
start-hbase.sh |

查看各个节点的HBase角色是否启动,如果通过jps查看node02, node03,node04的HRregionserver没有启动,可能是因为主从节点时间不一致,需要回到Step2将时间统一然后再次启动HBase
Step14. 测试主备切换
# 可以查当前HMaster的pid并kill掉 |
Step13. 访问HBase
1)通过网页node01:60010以及node05:60010进行访问
2)通过命令行访问
hbase shell |
其中伪分布式创建的表在全分布式中查不到,因为伪分布式创建的文件是在本地,而全分布式创建的文件是在HDFS
HBase应用
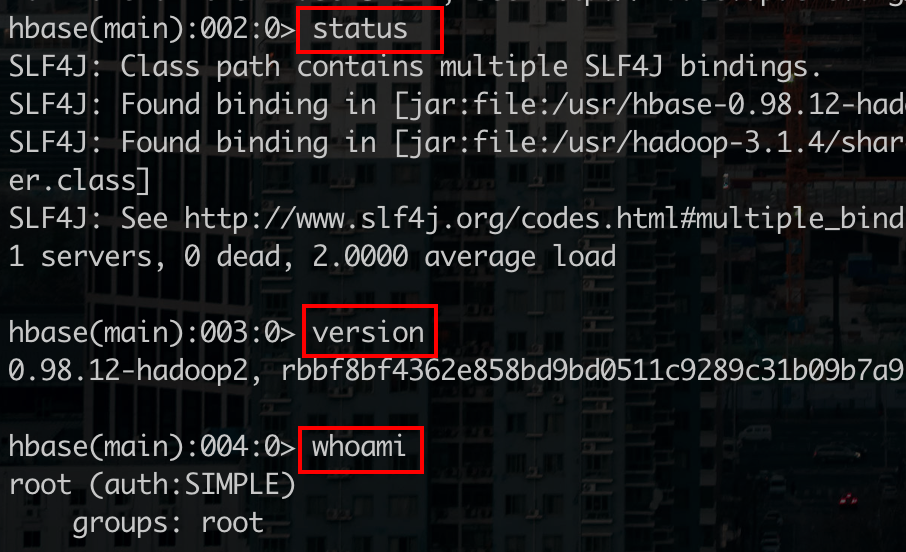
通过help可以查看HBase的使用命令,下面介绍HBase几种常用的命令
General
# 查看节点状态命令 |
DDL
# 创建表 |

# 禁用表 |
DML
插入数据
# 通过表名,rowkey,列族,列名以及value来插入数据 |
删除数据
# 通过表名,rowkey以及列族来删除数据 |
修改数据
# 将rowkey=2222中name=xiaohong的数据改成zhiling |
修改数据后,虽然xiaohong数据不显示但还存在,只是标记了失效且无法回滚,后续merge的时候会自动删除xiaohong的数据
查询数据
# 查看指定rowkey下的数据 |
Tools
HBase表psn的HDFS存储路径/home/testuser/hbase/data/default/psn/下存在一串英文编码的文件名,该名就是表psn对应的R Region名,可以通过主节点IP:60010来确定。如果psn表只插入少量数据,那么Region文件夹中的列族文件夹可能为空,因此还没有进行merge操作,即数据还在内存的MemStore中,这时可以手动将其flush进磁盘
flush 'psn' |
然后在命令行查看flush后列族文件下的文件内容
hbase hfile -p -f /hbase/data/default/psn/... |
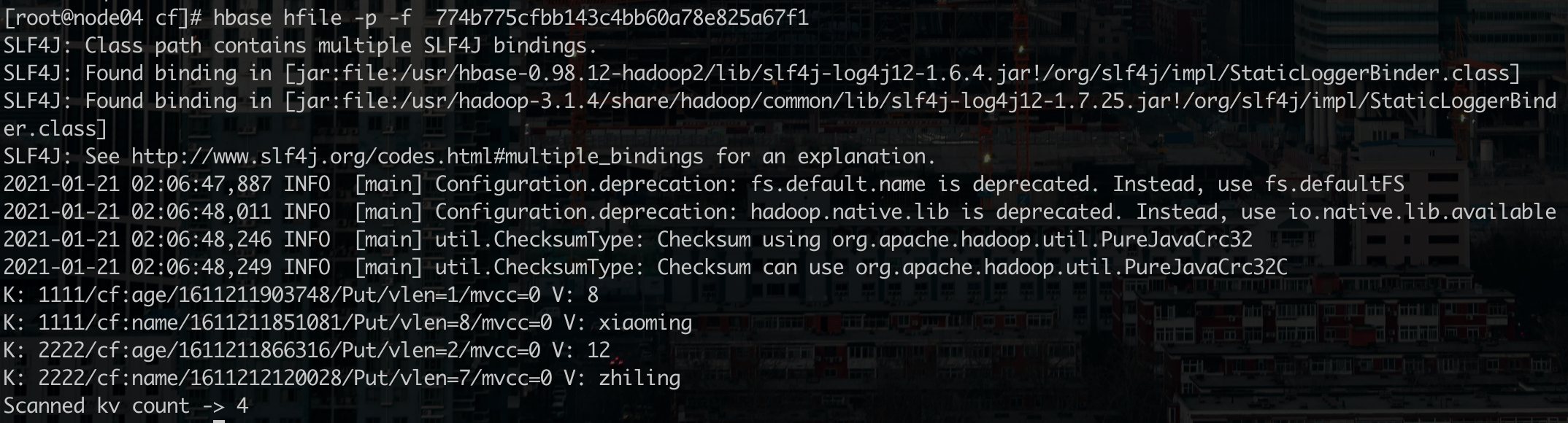
修改数据后再次手动flush,相应列族下新增一个仅用来存储修改数据的文件,第三次修改数据后再次手动flush,相应列族将最新修改数据以及其他未修改数据文件merge成一个文件