说在前面的话
Redis是基于key-value格式存储的高性能NoSQL数据库。本文主要从从架构,数据模型的角度介绍Redis~
Redis发展史
曾经在没有数据库的时代只能用记事本,.csv等文件作为存储数据的介质,如果需要查找某个小文件中的某个字符串要用grep进行全量IO匹配,后来伴随着科技的进步产生的数据量也越来越大,如果还用全量IO匹配显得有些吃力,因此出现了新的技术DataBase,后来就有了将CRUD效率大大提升的关系型数据库
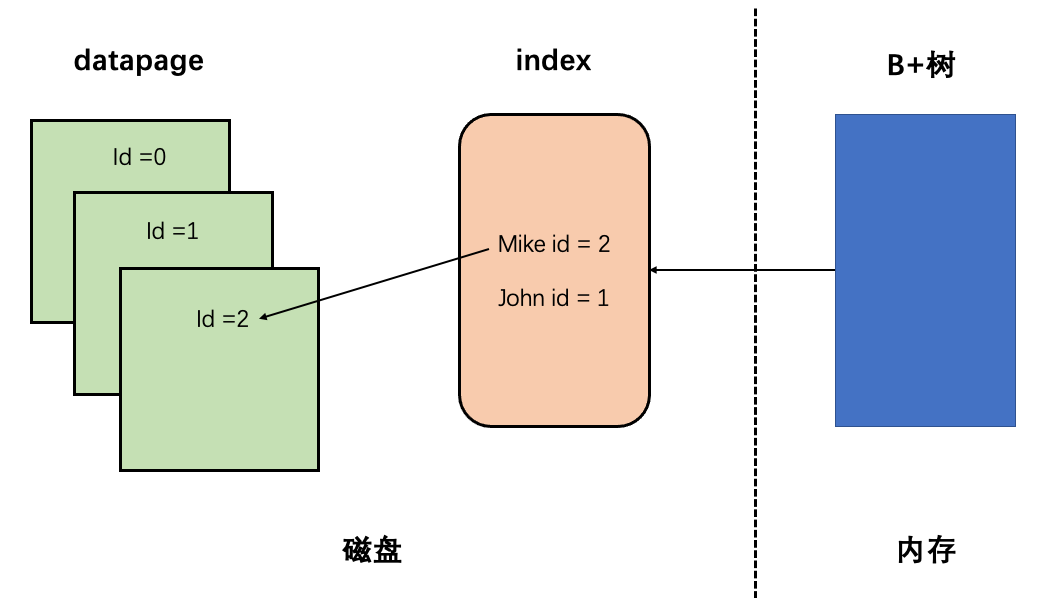
关系型数据库是如何提升CRUD效率的呢?首先将数据打散成4k大小并有独立id的datapage,接下来针对某字段创建4k大小的index表,这样就可以根据index表中的字段对应的datapage的id,快速定位到指定的datapage进行查找,最后内存中的B+树负责定位到index表来进行快速查询,这样关系型数据库就做到了提升CRUD效率的目的啦~ 其中在行数据库创建表的时候需要指明数据类型以及字段个数,这样就可以计算每行的字节数,进而可以根据datapage的大小计算datapage中包含多少行数据,还有index表虽然创建的越多对查询越有好处,但针对更新操作的复杂度就会变高,所以需要针对常用的字段来建立index表。
随着用户高并发连接磁盘数据库的请求仍然会使IO达到瓶颈,所以有了将数据直接放到内存中的想法并出现了内存数据库memcached以及HANA,但HANA的问题是太贵了买不起,后来非关系型数据库Redis诞生了。Redis把数据分成热数据和冷数据,将热数据放到内存并将冷数据放到磁盘。比如每个人都有很多QQ账号但并不是都经常用,Redis将活跃的账号放到内存数据库并且将不活跃的账号放到磁盘数据库,当用户第一次登录QQ服务器时如果在内存中没有账号数据,这时Redis会到磁盘里把账号数据取出放到内存中,等第二次登陆服务器时就直接使用内存里的账号数据。由于存在冷数据会被再次使用并放到内存的情况,因此也会存在内存撑爆的问题,Redis通过设置过期的方式解决了该问题,这样Redis就实现了不占用很高的内存也能做到加速查询的效果
Redis搭建
单节点安装
Step1. 安装gcc以及tcl
yum -y install gcc tcl |
Step2. 下载redis-2.18.8.tar.gz并解压到/usr/
tar -zxvf redis-2.18.8.tar.gz -C /usr/ |
Step3. 在/usr/redis-2.8.18目录下编译,创建指定目录并进行拷贝
make && make PREFIX=/usr/redis install |
执行过后可以在/usr/redis/下面查到生成了bin文件
Step4. 在/etc/profile配置环境变量
export REDIS_HOME=/usr/redis |
配置保存后执行
source /etc/profile |
Step5. 进入/usr/redis-2.18.8启动redis-server
./redis-server |
每次都到指定目录手动启动服务很麻烦,所以可以直接在/usr/redis-2.18.8/utils/安装服务
./install_server.sh |
在安装过程中会出现当前实例的配置信息,日志信息以及数据信息所在的存储路径,其中Redis在一台节点上可以存在多个实例,每个实例就是一个服务,每个服务都有一个独立的端口号
Step6. 运行Redis
# 进入Redis客户端 |
Step7. 退出Redis
# 法1 |
Redis数据类型
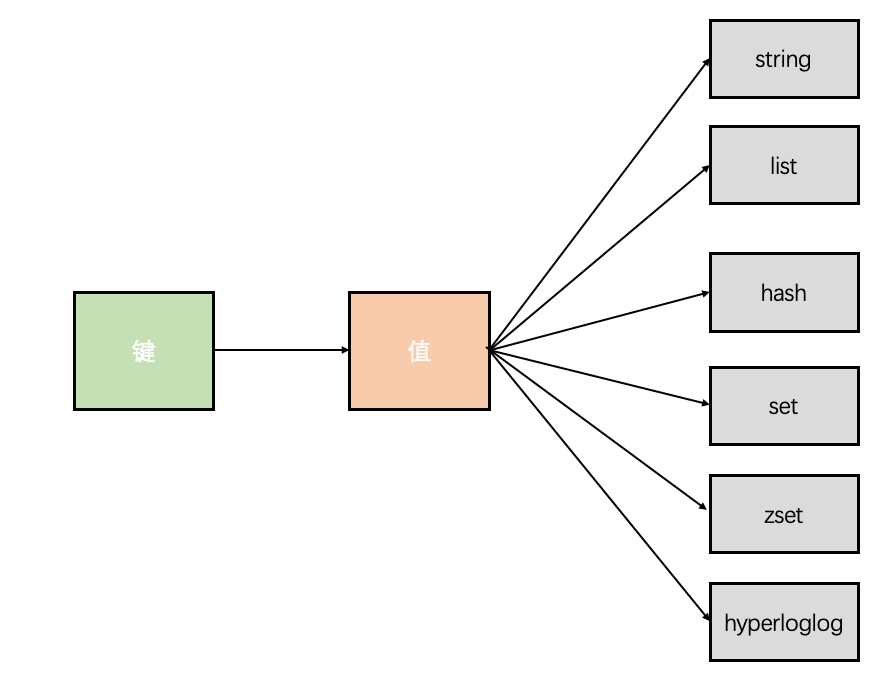
Memcached只支持字符串类型,如果将数组存到Memcached是不可行的,需要转成数组形式的字符串才能存入,而且读的时候也需要将整个字符串取出并通过split转成数组,但是Redis支持丰富的数据类型,比如string,hashes,lists,sets,zset,bitmaps,hyperloglogs和地理空间等,即Redis是强语言类型,其中丰富的数据类型指的是value,而key只能是string。Redis的key是二进制安全的,即底层是用二进制字节数组存储的,这意味着任何格式的二进制序列数据都可以作为key值,比如从简单的字符串到.jpeg格式的图片内容都可以作为key,其中空字符串也是有效的key值。key本身会带有一些属性,比如strlen, object encoding等。Redis中只存在(key,value)这种数据形式,无论存储值,修改值以及删除值,都离不开key,key的取值一般不要太长也不要太短,太长会占用内存,太短可读性会差。
帮助命令
# 帮助命令 |
# 将指定数据类型下的全部命令列出来 |
string类型
基本操作
# set操作 |
匹配keys
# 分别匹配1个,2个以及3个字符的key |
Flush
# 将所有数据库的keys都刷掉 |
多数据库切换
每个redis实例可以拥有多个数据库,一个端口可以有16个数据库
# 默认进入的是0号数据库 |
中文编码
# 终端默认是utf-8编码集,其中编码集是字符到计算机语言的映射,最开始是美国人发明的包含128个字符的ASCII码,后来出现了国标码GBK以及万国码utf-8 |
我们可以通过终端的设置直接切换编码集
# 切换成GBK编码之后设置一个新的值 |
BitMap
# key后面第1个参数是offset,第2个参数value |
# 返回k1的值是ASCII码第64位对应的@ |