说在前面的话
资源管理和任务调度框架Yarn可以为很多计算框架服务,比如MapReduce以及Spark,本文从架构,执行流程以及集群搭建来介绍Yarn
Yarn架构介绍
Yarn主要负责解耦资源管理和任务调度
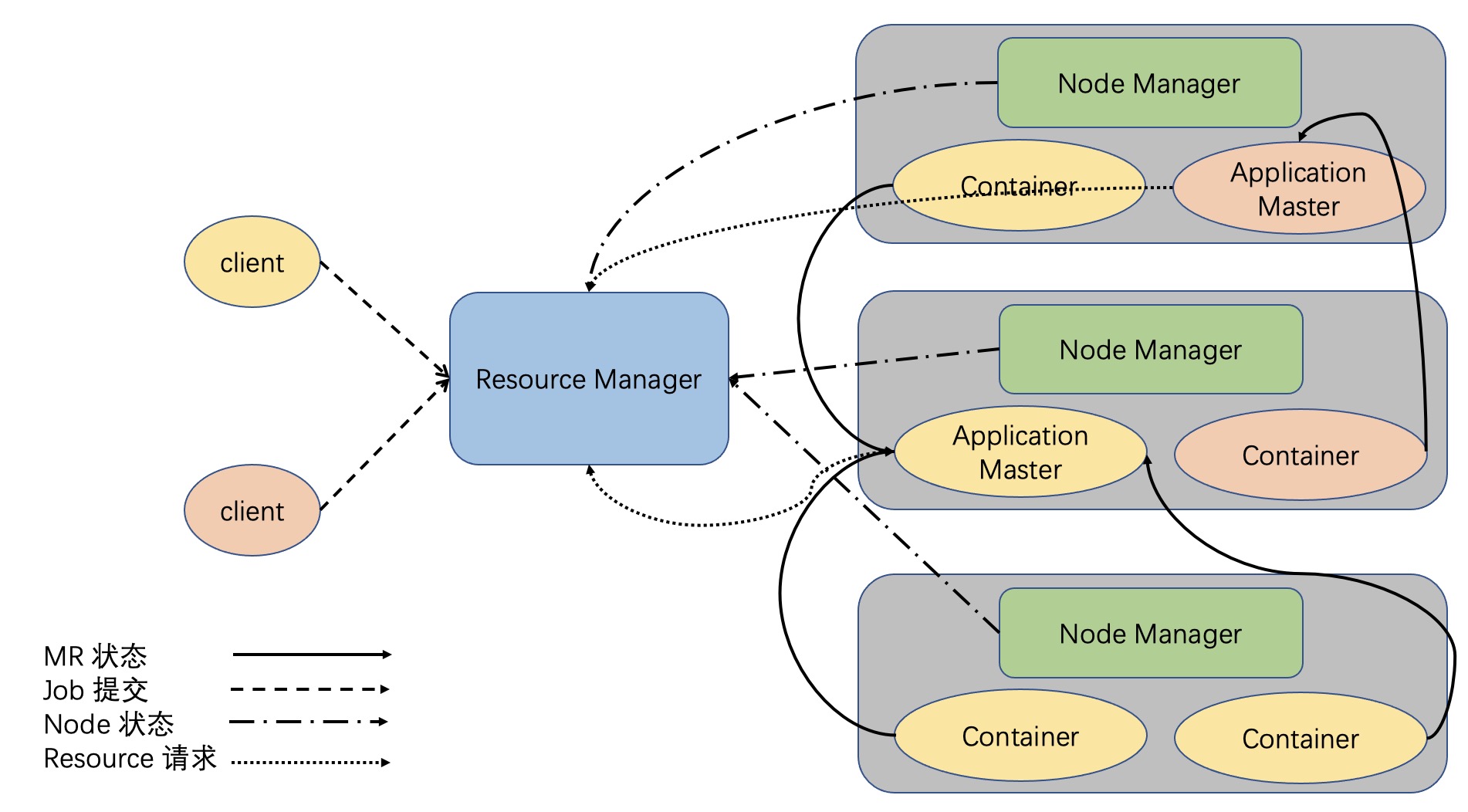
Resource Manager
是Yarn集群的核心,负责集群节点资源管理
Node Manager
负责向ResourceManager汇报资源,管理Container生命周期,其中计算框架中的角色都以Container表示。NodeManager和DataNode一一对应,每个DataNode旁边都有一个NodeManager保证了计算向数据移动。NodeManager负责和ResourceManager做心跳,即将节点资源使用情况汇报给ResourceManager,这样ResourceManager就可以掌握全局集群的资源使用情况啦~
Container
代表一台节点,和NodeManager一一对应。默认情况下NodeManager启动线程监控Container大小,如果Container超出申请资源大小会被kill掉,但是失败后任务调度者ApplicationMaster 会通过失败重试机制再次向资源管理者ResourceManager重新申请资源并调度,其中Yarn分配Container的大小默认为1G。虽然HDFS数据块默认是128M,但假如有连接数据库操作,就有可能导入几个G的数据到内存进而超过Container大小,因此超内存的场景一般都是人为造成的
Client
负责请求ResourceManager创建Application Master
架构优点
曾经一个JobTracker调度所有的作业,现在通过AM解决了作业调度的单点故障以及调度压力过大问题,就算上述架构图中两个Client分别是MR作业和Spark作业也是没问题的,不过RM仍然会存在单点故障问题,但可以通过在不同节点上分别做主RM和备RM并用zookeeper进行协调,即通过HA的方式来解决RM的单点故障问题。Yarn框架保证了每个作业都是互相不干预的独立程序
Yarn执行流程
Step1. Client访问RM并发出想计算一批数据的请求
Step2. RM会在所有节点中挑选一个不忙的节点创建一个AM,AM相当于JobTracker的任务调度功能,RM相当于JobTracker中的资源管理功能,其中AM和TaskTracker不同,因为AM是为固定作业创建的短服务,而TaskTracker是长服务
Step3. AM从HDFS中取回切片清单并向RM申请Map可以运行的地方
Step4. RM会给AM指定一批Container来运行Map
Step5. Container将计算结果返回给AM
集群搭建
本文仅介绍Yarn的高可用搭建,假设现在有4个节点,每个节点的角色如下
| NN-1 | NN-2 | DN | ZK | ZKFC | JNN | RM | NM | |
|---|---|---|---|---|---|---|---|---|
| node01 | ✔︎ | ✔︎ | ✔︎ | |||||
| node02 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ||
| node03 | ✔︎ | ✔︎ | ✔︎ | ✔︎ | ✔︎ | |||
| node04 | ✔︎ | ✔︎ | ✔︎ | ✔︎ |
Step1. 在4台节点上安装jdk1.8
Step2. 在/usr/hadoop-3.1.4/etc/hadoop/hadoop-env.sh的末尾新增Yarn的RM以及NM的用户名
export JAVA_HOME=/usr/java/jdk1.8.0_261 |
Step3. 在/usr/hadoop-3.1.4/etc/hadoop/mapred-site.xml配置mapreduce所在的资源框架
<configuration> |
Step4. 在/usr/hadoop-3.1.4/etc/hadoop/yarn-site.xml配置yarn集群各个角色
<configuration> |
Step5. 将上述配置文件发送到其他节点
scp hadoop-env.sh mapred-site.xml yarn-site.xml node02:`pwd` |
Step6. 在node01上启动Yarn集群
# HDFS集群和Yarn集群是是独立的,各自启动互不影响 |
其中NodeManager和DataNode都是从角色,所以在Node01上启动Yarn集群会复用Hadoop高可用搭建时配置的worker,即自动在Node02,Node03,Node04上启动NodeManager
Step7. Web访问Yarn集群
# 备用的RM节点无法通过node04:8088无法访问 |
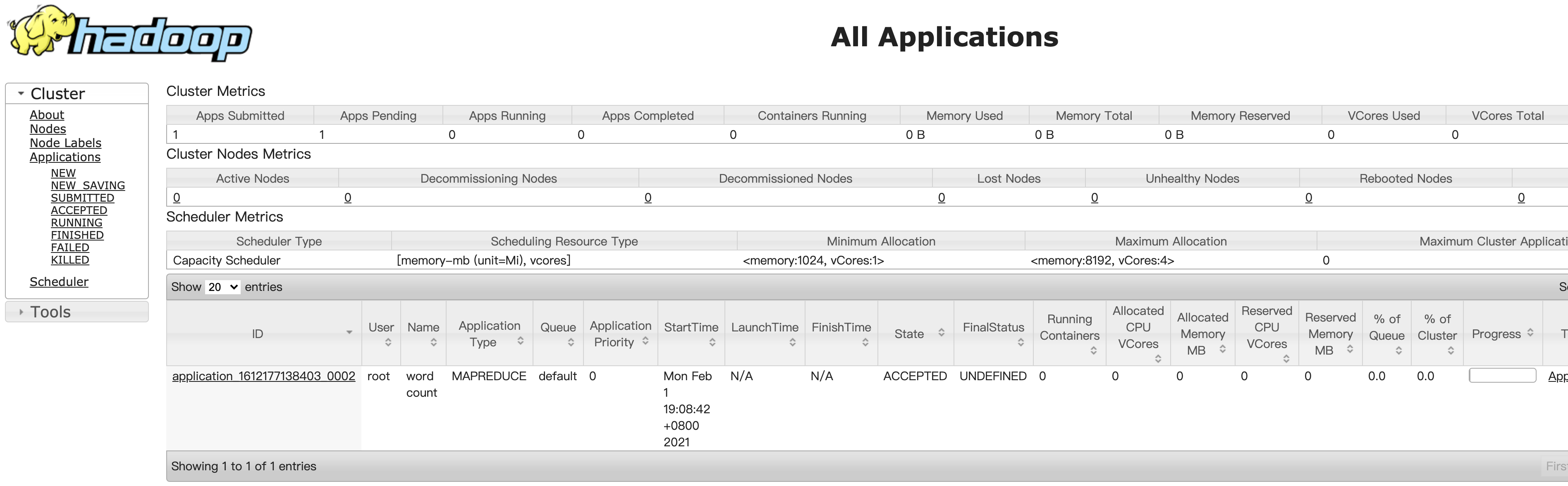
我们可以在/usr/hadoop-3.1.4/share/hadoop/mapreduce中使用Hadoop自带的的wordcount测试代码
# 最后一个参数,即MapReduce计算结果的输出目录必须是不存在或者空 |

其中第一个文件_SUCCESS表示计算成功的标识,第二个文件中r代表Reduce的输出,每个Reduce都对应一个文件,Yarn框架默认只有一个Reduce。如果存在名字中带有m的文件则代表Map的输出,我们有时只会保留map的结果,比如只做过滤操作
# 可用hadoop的cat方法查看最终计算结果 |