ESMM简介
阿里妈妈团队在2018年的SIGIR上发表论文《Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate》,这篇文章是基于多任务学习的思路提出了新的CVR预估模型ESMM,解决了现实生活中CVR预估面临的样本数据稀疏以及样本选择偏差的问题
CVR面临的挑战
在本文提出之前,CVR预估面临以下两个挑战。针对传统的CVR模型 p(z=1|y=1,x),训练样本是已点击的用户样本,这部分样本仅仅是推断空间的一部分(就是上图中提到的bias problem),目前CVR模型遇到的问题:样本有偏以及数据稀疏
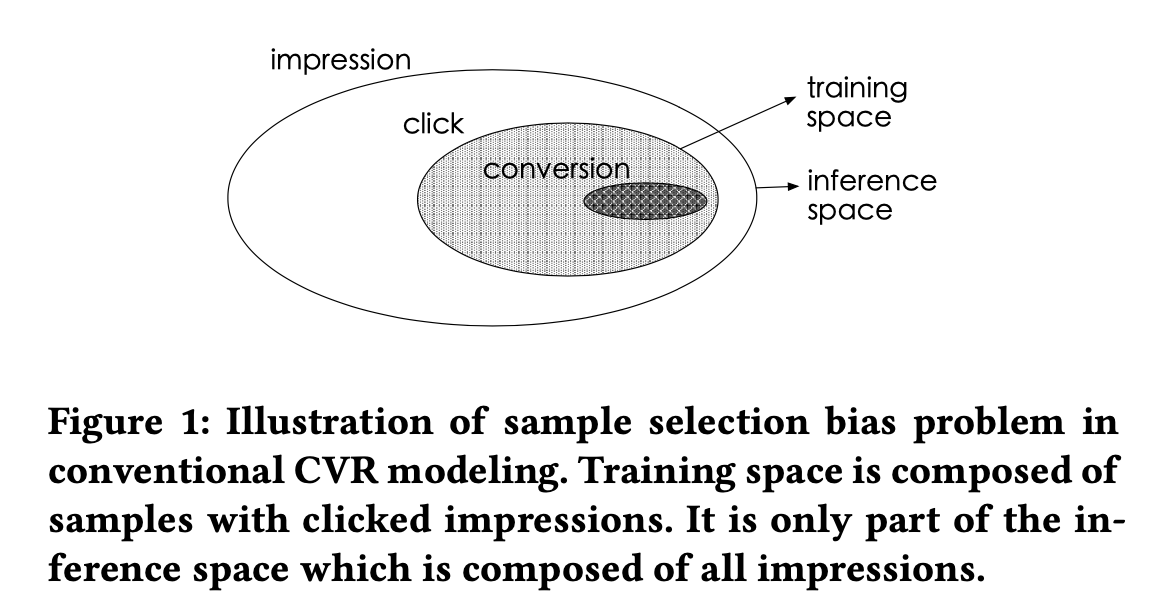
符号描述
- :表示观测数据集,其中是来自于分布并且定义域为 X Y Z的,其中X表示特征空间,Y和Z表示标签空间,N表示样本总量。
- 表示观测的特征向量,它是一个高维稀疏向量,比如user字段,item字段等
- 和表示二分类标签,其中表示点击,表示转化,表示依赖的序列,因为转化事件发生的时候总是会有点击
理论基础

模型介绍
ESMM是一个双塔模型,它引入两个辅助任务 CTR 以及 CTCVR 消除了之前传统的CVR问题并同时得到了CVR模型,在ESMM中训练的模型就是针对全空间样本S来训练的,通过估计CTR以及估计CTCVR来得到CVR

其中pctr如果过小的话,容易引起数字不稳定,但是ESMM通过乘法形式避免了该问题,通过该形式可以确保概率在[0,1],如果按照上述的除法形式,得到的结果可能会大于1
损失函数
ESMM的损失函数由CTR以及CTCVR的损失函数组成

其中和分别是CVR网络和CTR网络的参数,是交叉熵损失函数,在CTR任务中,点击表示正样本,其余的表示负样本;在CVR任务中,点击并且转化的表示正样本,其余的表示负样本。
实战篇
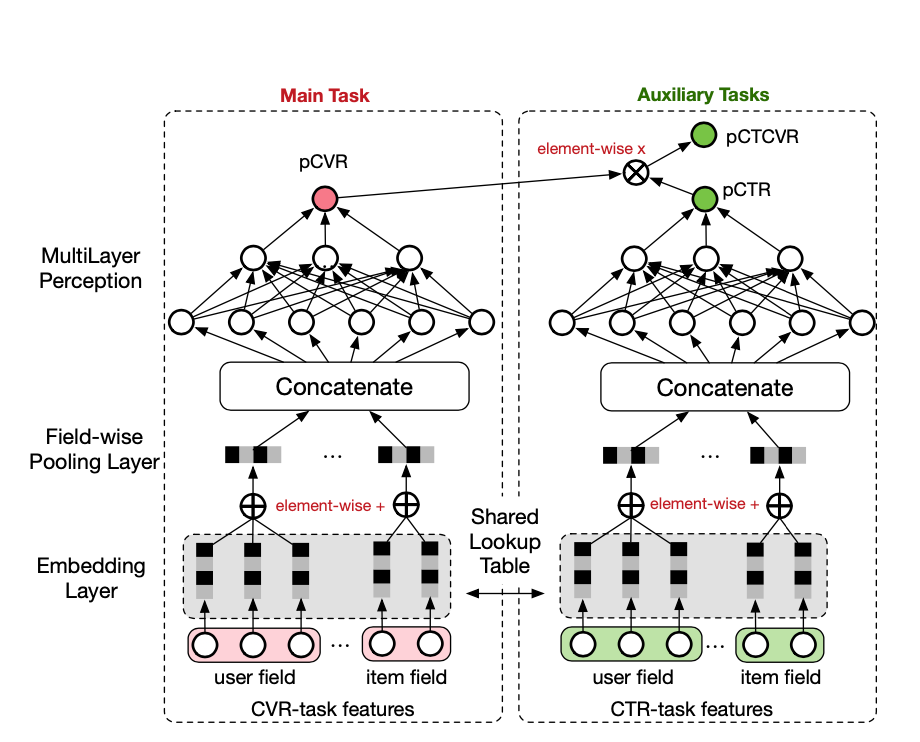
整个模型的结构非常的简单清晰,分为一个main task和一个auxiliary task,其中main task依然是传统的cvr转化模型,auxiliary task通过shared lookup table与main task共享embedding层,缓解了数据稀疏导致的embeding学习表达较弱的问题,ctr预估模型主要用到了impression数据,因此共享embedding层可以为cvr预估模型带来一些impression相关的数据信息,这样就解决了样本偏差的问题
CVR模型构建
Step1 输入层
对于样本中的每个field,比如user_field,item_field,需要分别创建不同的input,为了后续的concatenate做铺垫
# 其中user_field_size表示特征维度 |
Step2 Embedding层
Embedding层的构建是本文的亮点,因为这里用到了”shared lookup table”,也就是输入层到共享层的权重矩阵
shared_user_embds = tf.keras.layers.Embedding(input_dim=user_feat_size, output_dim=64, name="shared_user_embds")(cvr_user_input) |
Step3 Pooling层
这里需要将所有的embedding向量求和,这里暂时用取平均的方法代替求和,后期优化该部分算法
cvr_user_pool = tf.keras.layers.GlobalAveragePooling1D(name="cvr_user_pooling")(shared_user_embds) |
Step4 concatenate层
将池化后的embedding向量首尾拼接
cvr_dense_feature = tf.keras.layers.concatenate([cvr_user_pool, cvr_item_pool], axis=-1, name="cvr_concatenate") |
Step5 全连接层
# 第一个全连接隐藏层 |
CTR模型构建
在原论文中描述CVR和CTR是结构相同的Base模型,因此对于构造过程不再赘述

ESMM模型
通过将CVR和CTR的输出相乘就可以得到我们CTCVR,进而可以构建出ESMM模型
ctcvr_output = tf.multiply(cvr_output, ctr_output, name="ctcvr_output") |
基于ESMM的特征Embedding
这里主要描述通过ESMM模型将样本特征进行embedding化。当训练好ESMM模型后,我们可以获取embedding层各个field的embedding权重矩阵,进而可以根据样本产出对应的Embedding向量

具体生成Embedding步骤如下
Step1 找到embedding层的index

Step2 构建新模型embds_model

Step3 输入样本产出embedding向量

其中embedding维度=7,样本的特征维度=4,所以上述1条样本产出的embedding向量构成的矩阵维度(4,7)
这样就达到了基于ESMM算法进行特征embedding的目的