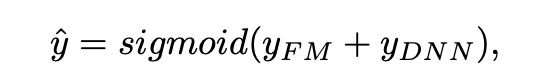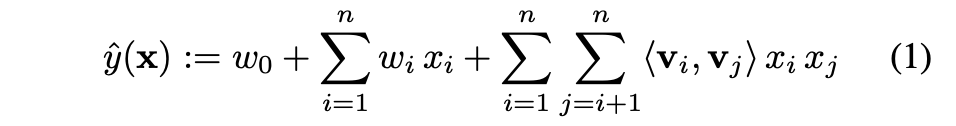DeepFM简介 在推荐系统中CTR预估是至关重要的,CTR预估主要目的是估计用户点击推荐商品的概率。但目前提出的CTR预估模型都有不足之处,而本文提出的DeepFM模型相比于之前的模型有以下明显的优势
不需要特征工程
不需要预训练
包含高阶交互特征(Deep部分实现)
包含低阶交互特征(FM部分实现)
模型介绍
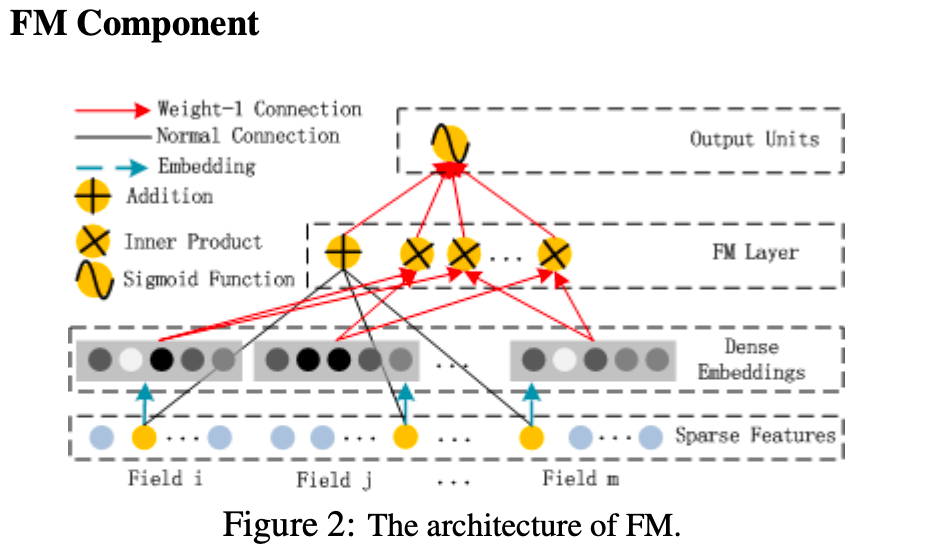
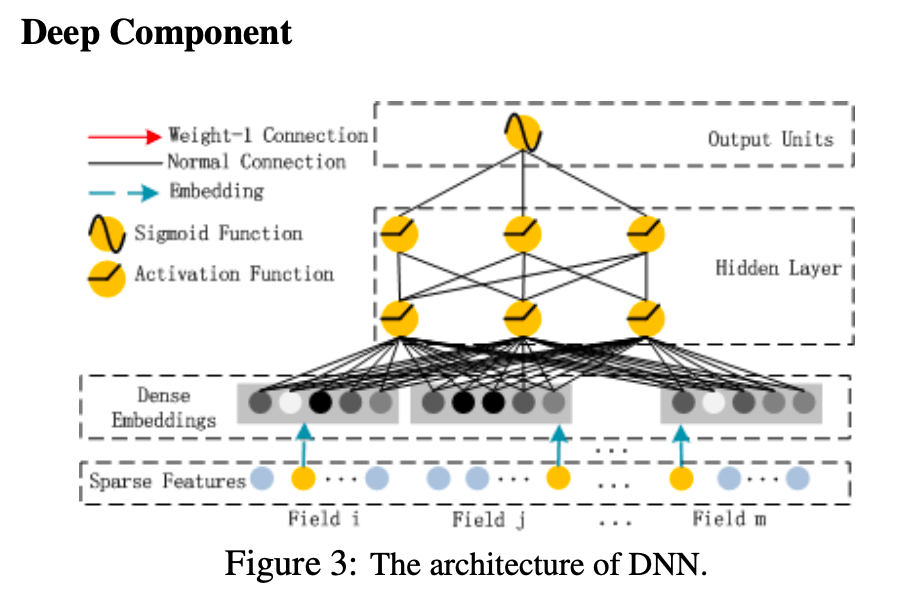
DeepFM由两部分组成,分别是FM component以及Deep component
其中原始FM模型为
经过整理可得到
但在本文中二阶交互特征 针对的是embedding向量ei和ej,而不是原始输入xi和xj
实战篇 整个模型的结构非常清晰,分成embedding层,FM component以及Deep component部分
Step1 Embedding层 将输入样本进行one-hot编码之后转成维度统一的embedding向量,每个field都会对应一个embedding向量
embeddings = tf.nn.embedding_lookup(weights['feature_embeddings' ], feat_index) reshaped_feat_value = tf.reshape(feat_value, shape=[-1 , dfm_params['field_size' ], 1 ]) reshaped_feat_value = tf.cast(reshaped_feat_value, "float32" ) embeddings = tf.multiply(embeddings, reshaped_feat_value)
Step2 FM component 根据原始输入得到一阶交互特征,根据embedding向量得到二阶交互特征向量
fm_first_order = tf.nn.embedding_lookup(weights['feature_bias' ], feat_index) fm_first_order = tf.reduce_sum(tf.multiply(fm_first_order, reshaped_feat_value), 2 ) summed_features_emb = tf.reduce_sum(embeddings, 1 ) summed_features_emb_square = tf.square(summed_features_emb) squared_features_emb = tf.square(embeddings) squared_sum_features_emb = tf.reduce_sum(squared_features_emb,1 ) fm_second_order = 0.5 * tf.subtract(summed_features_emb_square, squared_sum_features_emb)
Step3 Deep component y_deep = tf.reshape(embeddings, shape=[-1 , dfm_params['field_size' ] * dfm_params['embedding_size' ]]) for i in range(0 , len(dfm_params['deep_hidden_layers' ])): y_deep = tf.add(tf.matmul(y_deep, weights["weight_%d" %i]), weights["bias_%d" %i]) y_deep = tf.nn.relu(y_deep)
Step4 输出层 这里将FM部分和Deep部分结合起来统一输出
if dfm_params['use_fm' ] and dfm_params['use_deep' ]: concat_input = tf.concat([fm_first_order, fm_second_order, y_deep], axis=1 ) elif dfm_params['use_fm' ]: concat_input = tf.concat([fm_first_order,fm_second_order], axis=1 ) elif dfm_params['use_deep' ]: concat_input = y_deep output = tf.nn.sigmoid(tf.add(tf.matmul(concat_input, weights['concat_weight' ]), weights['concat_bias' ])) loss = tf.losses.log_loss(tf.reshape(y_train_label, (-1 ,1 )), output) optimizer = tf.train.AdamOptimizer(learning_rate=dfm_params['learning_rate' ], beta1=0.9 , beta2=0.999 , epsilon=1e-8 ).minimize(loss) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) for i in range(15 ): epoch_loss, _= sess.run(fetches=[loss, optimizer], feed_dict={feat_index:train_feat_index, feat_value:train_feat_value, label:y_train_label}) print("epoch %s,loss is %s" % (str(i),str(epoch_loss))) res = sess.run(weights) print("embedding矩阵的维度为" ) print(res['feature_embeddings' ].shape) print(res.keys())
样例篇 这里主要描述通过训练好的DeepFM模型来进行特征挖掘,具体方法如下
其中embedding维度=8,样本的特征维度=4,所以上述1条样本产出的embedding向量构成的矩阵维度(4,8)
这样就达到了基于DeepFM算法进行特征挖掘的目的