业务案例
互联网企业A 为了提高用户对金融产品“小小贷”购买的转化率,想和金融企业B达成合作。互联网企业A有用户上网行为特征X1、X2、X3,金融企业B有用户的信用特征X4、X5和标签Y,这样就可以把两边的特征结合起来,并通过机器学习来提高“小小贷”购买的转化率。但是在合作的过程发现一个问题,那就是企业之间无法进行互通数据 !!!
NeoFL概述
用户数据的隐私问题越来越受到重视,未来数据孤岛的问题也会越来越普遍,这对现有的传统机器学习的模式提出了挑战,因此一种全新的机器学习模式诞生了,那就是联邦学习。联邦学习源于2016年由谷歌正式提出的算法模型[1],在2017年[2]首次定义了联邦学习。
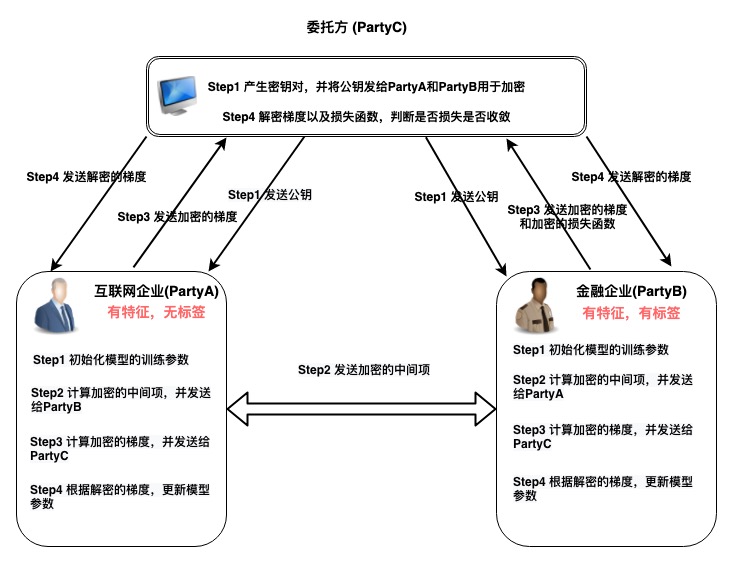
目前市面上存在一些开源的联邦学习框架,但每个框架都存在一定的问题,比如微众银行的FATE虽然称作是工业级的框架, 但配置多,操作起来特别复杂;百度提出的PaddleFL,存在初学者上手难,文档理解难的问题。因此本着取其精华弃其糟粕的想法,小编未依赖任何底层框架,从0到1手动实现了基于半同态加密的纵向联邦模式的逻辑回归算法框架 — NeoFL。我们通过NeoFL就可以解决最开始提出的企业之间无法进行互通数据的问题。NeoFL实现的大致流程如下图👇
算法介绍
符号说明
设有n个训练样本,Features和 Label分别表示成
和
其中$y=0$和$y=1$分别表示表示用户不购买和购买金融产品,的每行代表每个用户的特征向量。
损失函数
逻辑回归模型的损失函数和梯度公式中包含指数运算,如果采用半**同态加密**算法,需要对原始的公式进行变换,使其变成只包含加法和数乘的形式,这里我们可以通过泰勒展开来对指数形式的表达式进行近似。
常用的逻辑回归损失函数为
根据可以得到
那么在 处的泰勒展开式可以写成
因此,将损失函数进行二阶泰勒展开
那么损失函数的梯度表达式为
根据PartyA和PartyB,将梯度分成上下两部分
这样就实现了分别在 PartyA 和 PartyB 计算梯度的目的。
流程
为了后续描述方便,我们将互联网企业A,金融企业B以及中间委托人C,分别命名为PartyA,PartyB以及PartyC
| 步骤 | PartyA | PartyB | PartyC |
|---|---|---|---|
| Step1 | 初始化 PartyA模型的训练参数 | 初始化 PartyB模型的训练参数 | 生成秘钥对,并分发公钥🔑给 |
| Step2 | 计算加密的中间项,将其发送给PartyB | 计算加密的中间项,并将其发送给PartyA | |
| Step3 | 计算加密的梯度,将带有随机项的加密梯度 其发送给PartyC | 计算加密的梯度,将带有随机项的加密梯度 其发送给PartyC | 接收来自PartyA和PartyB的加密梯度项 |
| Step4 | 根据解密的梯度获取,并更新 PartyA 的模型参数 | 根据解密的梯度获取 ,并更新 PartyB 的模型 | 将加密的梯度进行解密,并分别发送给PartyA和PartyB 计算解密后的loss,并判断loss是否收敛,若收敛增本轮迭代结束,否则重复Step2 |
实验
为了评估NeoFL中纵向联邦逻辑回归的效果,我们将未进行联邦学习的逻辑回归算法作为对照组,其中对照组中针对损失函数是否进行泰勒近似分成对照组1和对照组2。
本文是基于sklearn中的乳腺癌数据集生成的模拟数据来进行实验,通过使用相同的训练数据集进行模型训练,观察损失值的下降曲线以及在测试集上的模型效果。
损失变化
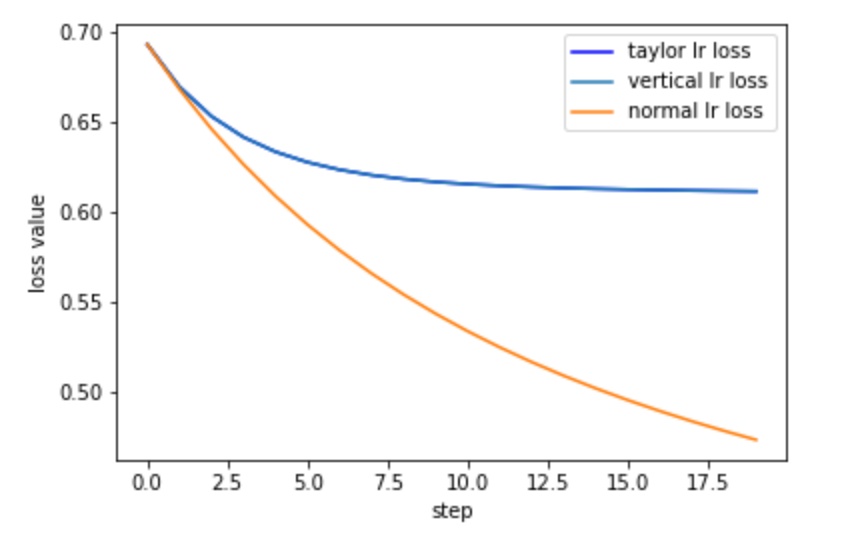
其中上述曲线中,横轴代表算法的迭代次数,纵轴表示每次迭代对应损失值,其中每条曲线的含义如下:
(1) vertical lr loss: 表示纵向联邦学习LR模型训练过程中的损失变化曲线;
(2) taylor lr loss: 表示标准的LR模型训练过程中的损失变化曲线,其中损失函数用泰勒展开来近似;
(3) normal lr loss: 表示标准的LR模型训练过程中的损失变化曲线。
模型效果
| 数据集 | 行数 | 特征数 | 纵向联邦LR的AUC | 标准LR的AUC(泰勒近似) | 标准LR的AUC |
|---|---|---|---|---|---|
| Breast Cancer | 426 | 30 | 训练集:0.9921 | 训练集:0.9921 | 训练集:0.9895 |
| Breast Cancer | 123 | 30 | 测试集:0.9843 | 测试集:0.9816 | 测试集:0.9816 |
由上述的损失变化以及模型效果可以看到,与标准的逻辑回归相比,NeoFL的纵向逻辑回归算法在保证各方数据隐私性的同时,实现了模型效果没有损失的目的。
展望
针对目前的联邦学习框架,还有进一步的优化空间,比如:
- 优化频繁通信带来的性能问题;
- 优化模型训练时中间数据落盘的存储问题;
- 增加惩罚项来缓解模型的过拟合,并解决增加惩罚项之后,损失会越来越大的问题。
参考文献
[1] H. Brendan M, Eider M. Federated Learning of Deep Networks using Model Averaging(2016). https://arxiv.org/pdf/1602.05629v1.pdf
[2] H. Brendan M, Eider M. Communication-Efficient Learning of Deep Networks from Decentralized Data(2017). https://arxiv.org/pdf/1602.05629.pdf
附录
在这一部分,小编向大家介绍下如何通过Python实现NeoFL中纵向联邦的逻辑回归算法🥳
参与方父类
我们首先需要创建各参与方的父类,主要用于保存模型的参数、中间的计算结果以及与其他参与方的连接状态
# 各参与方的父类 |
参与方子类
参与方A:在训练过程中仅提供特征数据
# 参与方A: 在训练过程中,仅提供特征 |
参与方B:在训练过程中,提供特征和标签
# 参与方B: 在训练过程中,提供特征和标签 |
参与方C: 在训练过程中,提供秘钥对
class PartyC(Party): |
纵向联邦LR
训练基于半同态加密的纵向联邦逻辑回归模型
def vertical_logistic_regression(XA_train,XB_train,y_train,config): |
实验样例
# 加载数据并分成训练集和验证集 |
为了与没有联邦学习的模型做对比,需要训练标准LR模型以及损失函数用泰勒展开近似的LR模型
# 标准逻辑回归 |
最后,我们可以将联邦学习的LR,标准的LR以及带有泰勒近似的LR模型的预测结果进行比较
# 联邦学习LR训练 |